Which protocol or open standard do you like or wish was more popular?
Which protocol or open standard do you like or wish was more popular?
There are a couple I have in mind. Like many techies, I am a huge fan of RSS for content distribution and XMPP for federated communication.
The really niche one I like is S-expressions as a data format and configuration in place of json, yaml, toml, etc.
I am a big fan of Plaintext formats, although I wish markdown had a few more features like tables.
ISO 8601 date format. Not because it's from a standards body, but because it's simple, sensible, clearly defined, easy to recognize, and very effective.
Date field placement in any order other than most-significant-digits-first is not only counterintuitive, but needlessly complicated to work with. Omitting critical information like the century is ambiguous and confusing.
We don't live in isolated villages any more. Mixing and matching those problems by accepting all the world's various regional and personal date styles, especially with no reliable indication of which ones apply in any given case, leads to the hodgepodge of error-prone date madness that we have today.
The 2024-09-02 format should be taught in schools and required in official documents. Let the antiquated date styles fall into disuse outside of art and personal correspondence, like cursive writing.
And it can be sorted alphabetically in all software. That's a pretty big advantage when handling files on a computer
I had the fortune of being hired to build up from zero my department, and one of the first "rules" I made was all dates are ISO-8601 and now every process runs with 8601, if you use anything different your code is going to fail eventually when it finds another column date in 8601.
I love this standard. If you dig deeper into it, the standard also covers a way to express intervals and periods. E.g. "P1Y2M10DT2H30M" represents one year, 2 months, 10 days, 2 hours and 30 mins.
I recall once using the standard when writing a cron-style scheduler.
I also like the POSIX "seconds since 1970" standard, but I feel that should only be used in RAM when performing operations (time differences in timers etc.). It irks me when it's used for serialising to text/JSON/XML/CSV.
Also: Does Excel recognise a full ISO8601 timestamp yet?
I also like the POSIX “seconds since 1970” standard, but I feel that should only be used in RAM when performing operations (time differences in timers etc.). It irks me when it’s used for serialising to text/JSON/XML/CSV.
I've seen bugs where programmers tried to represent date in epoch time in seconds or milliseconds in json. So something like "pay date" would be presented by a timestamp, and would get off-by-one errors because whatever time library the programmer was using would do time zone conversions on a timestamp then truncate the date portion.
If the programmer used ISO 8601 style formatting, I don't think they would have included the timepart and the bug could have been avoided.
Use dates when you need dates and timestamps when you need timestamps!
RFC 3339 is a simplified profile of 8601 that only covers YYYY-MM-DD style formatting, if you only ever use that format and avoid the things like "2024-W36" they're mostly interchangeable.
The week-of-year is far more relevant in Western Europe, and is used quite a bit in business. I have a Junghans watch that has a week complication.
It's an important format outside of the US, and gives ISO-8601 an edge as a standard of conformance.
For the newbies: RFC 3339 vs ISO 8601. Bookmark this site.
That looks like an interesting diagram, but the text in it renders too small to read easily on the screen I'm using, and trying to open it leads to a javascript complaint and a redirect that activates before I can click to allow javascript. If it's yours, you might want to look in to that.
The table below works, though. Thanks for the link.
7 digit years feels way to optimistic, but I'll be rooting for us.
I arrived to manage releases in a company, the previous manager named releases as "release04092016", as USA standard. My first recommendation was to name releases as "releaseyyyymmdd" so "release20160409". I was asked by another manager why to change that, so I showed her a sorted list of releases "git branches" and asked her, can you tell me there when was the last release? (a very common question) Of course, to find the last release you need to check the whole list because the mmddyyyy order is useless. The answer with yyyymmdd was immediate, just look at the last row.
Some countries already use it officially too :)
Also, you can sort by ascending file names
The year is the information that most of the time is the least significant in a date, in day to day use.
DDMMYY is perfect for daily usage.
DDMMYY is perfect for daily usage.
Except that DDMMYY has the huge ambiguity issue of people potentially interpreting it as MMDDYY. And it's not straight sortable.
My team switched to using YYYY-MM-DD in all our inner communication and documents. The "daily date use" is not the issue you think it is.
Your day to day use isn't everyone else's. We use times for a lot more than "I wonder what day it is today." When it comes to recording events, or planning future events, pretty much everyone needs to include the year. Getting things wrong by a single digit is presented exactly in order of significance in YYYY-MM-DD.
And no matter what, the first digit of a two-digit day or two-digit month is still more significant in a mathematical sense, even if you think that you're more likely to need the day or the month. The 15th of May is only one digit off of the 5th of May, but that first digit in a DD/MM format is more significant in a mathematical sense and less likely to change on a day to day basis.
IPv6. Stop engineering IoT junk on single-stack IPv4, you dipshits.
Ogg Opus. It's superior to everything in every way. It's free and there is absolutely no reason to not support it. It blows my mind that MPEG 1.0 Layer III is still so dominant.
It blows my mind that MPEG 1.0 Layer III is still so dominant.
Count the number of devices in use today that will never support Opus, and it might not blow your mind any longer. Also, AFAIK, the reference implementation still doesn't implement full functionality on hardware that lacks a floating point unit.
These things take time.
I remember using Xiph's integer implementation of Ogg Vorbis on my Nokia N-Gage (Symbian S60). I wonder if it's not a priority for Opus. IIRC, Opus is floats all the way down.
update: it exists.
https://wiki.xiph.org/OpusFAQ#Is_there_a_fixed-point_implementation?
IPv6. Stop engineering IoT junk on single-stack IPv4, you dipshits.
Amen
Out of curiosity, why ogg as opposed to other containers? What advantages does it have?
Definitely agree on the Opus part, but I am very ignorant on the ogg container.
Large ISPs still don't support it. It's a fucking travesty.
Love, love, opus. It's a fantastic format.
I setup my opnsense firewall for IPv6 recently with Spectrum as an ISP. I followed this howto from The Other Site:
Even as someone who has a background in networking, I'd have no idea how to figure some of that stuff out on my own (besides reading a whole lot and trying shit that will probably break my network for a weekend). And whatever else you might say about Spectrum, they have one of the saner ways to implement it; no 6to4 or PPPoEv6 or any of that nonsense.
I did set the config for a /54, but Spectrum still gave me a /64. Which you can't subnet in IPv6. Boo.
Oh, and I'm not 100% sure if the prefix is static or not. There's no good reason that it should change, except to make self-hosting more difficult, but I have a feeling I'll see it change at some point.
So basically, if this is confusing and limiting for power users, how are average home users supposed to do it?
There are some standardization things that could make things easier, but ISPs seem to be doing everything they can to make this as painful as possible. Which is to their own detriment. Sticking to IPv4 makes their networks more expensive, less reliable, and slower.
The metric system, f*ck the imperial system. Every scientist sticks to the metric system, and why are people even still having an imperial system, with outdated measurements like stones for weight blows my mind.
Also f*ck Fahrenheit, we have Celsius and Kalvin for that, we don't need another hard to convert temperature measurement.
You are allowed to say fuck here.
Imperial is used in thermodynamics industries because the calculations work out better.
Also f*ck Fahrenheit, we have Celsius and Kalvin for that,
Who is Kalvin? Did you mean kelvin?
One drawback of celsius/centigrade is that its degrees are so coarse that weather reports / ambient temperature readings end up either inaccurate or complicated by floating point numbers. I'm on board with using it, but I won't pretend it's strictly superior.
I'll fight you on fahrenheit. It's very good for weather reporting. 0° being "very cold" and 100° being "very hot" is intuitive.
Knowing whether it may snow or rain depending on whether you are below or above 0 is very useful though. 0 and 100 are only intuitive because you're used to those numbers. -20 bring very cold and 40 being very hot is just as easy.
0° being “very cold” and 100° being “very hot” is intuitive.
As someone who’s not used to Fahrenheit I can tell you there’s nothing intuitive about it. How cold is “very cold” exactly? How hot is “very hot” exactly? Without clear references all the numbers in between are meaningless, which is exactly how I perceive any number in Fahrenfeit. Intuitive means that without knowing I should have an intuitive perception, but really there’s nothing to go on. I guess from your description 50°F should mean it’s comfortable? Does that mean I can go out in shorts and a t-shirt? It all seems guesswork.
This is strictly untrue for many climates. Where I live in Canada, 0F is average winter day, 100F is record-breaking "I might actually die" levels of heat.
-30C to 30C is not any more complicated or less intuitive than -22F to 86F
Ask someone in the north of finland how hot is "very hot", and how cold is very cold. Then ask the same in middle Africa. Spoiler: it will vary alot.
It's completely bonkers that JPEG-XL is as good as it is and no one wants to actually implement it into web browsers
Adobe is backing the format, Apple support is coming along, and there are rumors that Apple is switching from HEIC to JPEG XL as a capture format as early as the iPhone 16 coming out in a few weeks. As soon as we have a full blown workflow that can take images from camera to post processing to publishing in JXL, we might see a pretty strong push for adoption at the user side (browsers, websites, chat programs, social media apps and sites, etc.).
Do you know QOI format ? I would appreciate your opinion about it.
What's so good about it?
- Existing JPEG files (which are the vast, vast majority of images currently on the web and in people's own libraries/catalogs) can be losslessly compressed even further with zero loss of quality. This alone means that there's benefits to adoption, if nothing else for archival and serving old stuff.
- JPEG XL encoding and decoding is much, much faster than pretty much any other format.
- The format works for both lossy and lossless compression, depending on the use case and need. Photographs can be encoded in a lossy way much more efficiently than JPEG and things like screenshots can be losslessly encoded more efficiently than PNG.
- The format anticipates being useful for both screen and prints. Webp, HEIF, and AVIF are all optimized for screen resolutions, and fail at truly high resolution uses appropriate for prints. The JPEG XL format isn't ready to replace camera RAW files, but there's room in the spec to accommodate that use case, too.
It's great and should be adopted everywhere, to replace every raster format from JPEG photographs to animated GIFs (or the more modern live photos format with full color depth in moving pictures) to PNGs to scanned TIFFs with zero compression/loss.
Basically smaller file sizes than JPEG at the same quality and it also automatically loads a lower quality version of the image before it loads a higher quality version instead of loading it pixel by pixel like an image would normally load. Google refuses to implement this tech into Chrome because they have their own avif format, which isn't bad but significantly outclassed by JPEG-XL in nearly every conceivable metric. Mozilla also isn't putting JPEG-XL into Firefox for whatever reason. If you want more detail, here's an eight minute video about it.
I think I would feel better using JPEG-XL where I currently use WebP. Here's hoping for wider support.
Good news! I believe the Ladybird Browser intends to include support for JPEG XL.
JSON5. it's basically just JSON with several QoL improvements, like comments, that make it usable as a format for human consumption (as opposed to a serialization format).
Objects may have a single trailing comma.
I just came.
I love that there's someone out there who's that passionate about JSON.
I hate grammers in anything that don't support trailing commas. It's even worse when it's supported in some contexts and not others. Like lists are OK, but not function parameters.
TMI
TIL this exists
ActivityPub :) People spend an incredible amount of time on social media—whether it be Facebook, Instagram, Twitter/X, TikTok, and YouTube—so it’d be nice to liberate that.
I mean, you're in the right place to advocate for that 😜
i'm a plan 9 from bell labs fan. Imagine how excited I was when wsl used 9P for its plumbing. then they scrapped it all for wsl2.
just, the power they managed to get out of those union mounts... your application wants access to the mouse? sure, here's a file named "mouse". it's got the coordinates in it. you want to draw to the screen? here's a file called like "bitmap" or whatever, just write to it. you want to start a process on another machine? just cd to it and start the process there. want to have the UI show up on your machine? symlink your bitmap file to that directory.
I also wish early web composability could have stayed and expanded. like, the old vlc embed player, which would just show up in your browser and could play any file inline? great stuff. Imagine if every application composed with everything else, like the android Activity and Intent concepts but for anything, just by virtue of living in the same os. need an image? just ask the os and it will present the user with many ways to procure an image, let the selected one run , and hand you back an image. you don't even have to care where from. in a way, it's what the arcan guy is doing with his experiments, although that's more for stitching together graphical pipelines.
Plan 9 even extended the "everything is a file" philosophy to networking, unlike everybody else that used sockets instead.
Depending where you use it, but often tables are available in markdown.
markdown table x y |markdown|table| |--|---| |x|y|Fixed..cos you could only see rendered and not code.
Markdown tables are terrible though. Try and put a code block in there. Adoc tables are amazing on the other hand, but much more verbose to write.
I fixed it for you (markdown tables support padding to make them easy to read):
markdown table x y |markdown|table| |--------|-----| |x |y |deleted by creator, who realised their misunderstanding
I'd argue this syntax is difficult to read, especially as it scales
The syntax is only difficult to read in their example.
I fixed their example here: https://programming.dev/comment/12087783
Since nobody's brought it up: MQTT.
It got pigeonholed into IoT world, but it's a pretty decent event pubsub system. It has lots lf security/encryption options, plus a websocket layer, so you can use it anywhere from devices, to mobile, to web.
As of late last year, RabbitMQ started suporting it as a supported server add-on, so it's easy to use it to create scalable, event-based systems, including for multiuser games.
I spun up a MQTT/Aedes/MongoDB stack on my network recently for some ESP32 sensors.
Fantastic protocol and super easy to work with!
MQTT is great! There are clients available in Python, JS, etc
I'm currently on the ZeroMQ boat. What made you go to Rabbit Mq? I need the Pair socket for zeroMq for a project.
Installed RabbitMQ for use in Python Celery (for task queue and crontab). Was pleasantly surprised it also offered MQTT support.
Was originally planning on using a third-party, commercial combo websocket/push notification service. But between RabbitMQ/MQTT with websockets and Firebase Cloud Messaging, I'm getting all of it: queuing, MQTT pubsub, and cross-platform push, all for free. 🎉
It all runs nicely in Docker and when time to deploy and scale, trust RabbitMQ more since it has solid cluster support.
Zigbee or really any Bluetooth alternative.
Bluetooth is a poorly engineered protocol. It jumps around the spectrum while transmitting, which makes it difficult and power intensive for bluetooth receivers to track.
I agree Bluetooth (at least Bluetooth Classic) is not very well designed, but not because of frequency hopping. That improves robustness and I don't see why it would cost any more power. The hopping pattern is deterministic. Receivers know in advance which frequency to hop to.
I'll give my usual contribution to RSS feed discourse, which is that, news flash! RSS feeds support video!
It drives me crazy when podcasters are like, "thanks for listening to our audio podcasts. We also have a video feed for our YouTube subscribers." Just let me have the video in PocketCasts please!
I feel you but i dont think podcasters point to youtube for video feeds because of a supposed limitation of RSS. They do it because of the storage and bandwidth costs of hosting video.
I'd think they'd get it back by not having to share their ad rev with Google. There's something to be said for the economies of scale Google benefits from but with cloud services that's not as relevant as it was.
I just wrote a YouTube scraper and exported to RSS and into my podcast client. Using YouTube any other way is masochism in comparison.
PGP or GPG, however you spell it. You can encrypt stuff, protect your email from prying eyes!
Also FOSS in general.
The tooling around it needs to be brought up to snuff. It seems like it hasn't evolved much in the last 20+ years.
I had a small team make an attempt to use it at work. Our conclusion was that it was too clunky. Email plugins would fool you into thinking it was encrypted when it wasn't. When it did encrypt, the result wasn't consistently readable by plugins on the receiving end. The most consistent method was to write a plaintext doc, encrypt it, and attach the encrypted version to the email. Also, key servers are setup by amateurs who maintain them in their spare time, and aren't very reliable.
One of the more useful things we could do is have developers sign their git commits. GitHub can verify the signature using a similar setup to SSH keys.
It's also possible to use TLS in a web of trust way, but the tooling around it doesn't make it easy.
Huge fan of PHP...I mean PGP, oh god auto correct, you scary 😳
This isn't exactly what you asked, but our URI/URL schema is basically a bunch of missed opportunities, and I wish it was better designed.
Ok so it starts off with the scheme name, which makes sense. http: or ftp: or even tel:
But then it goes into the domain name system, which suffers from the problem that the root, then top level domain, then domain, then progressively smaller subdomains, go right to left. www.example.com requires the system look up the root domain, to see who manages the .com tld, then who owns example.com, then a lookup of the www subdomain. Then, if there needs to be a port number specified, that goes after the domain name, right next to the implied root domain. Then the rest of the URL, by default, goes left to right in decreasing order of significance. It's just a weird mismatch, and would make a ton more sense if it were all left to right, including the domain name.
Then don't get me started about how the www subdomain itself no longer makes sense. I get that the system was designed long before HTTP and the WWW took over the internet as basically the default, but if we had known that in advance it would've made sense to not try to push www in front of all website domains throughout the 90"s and early 2000's.
Then don’t get me started about how the www subdomain itself no longer makes sense. I get that the system was designed long before HTTP and the WWW took over the internet as basically the default, but if we had known that in advance it would’ve made sense to not try to push www in front of all website domains throughout the 90"s and early 2000’s.
I have never understood why you can delegate a subdomain but not the root domain, I doubt it was a technical issue because they added support for it recently via
SVCBrecords (But maybe technical concerns were actually fixed in the decades since)Don't worry, in 5 or 10 years Google will develop an alternative and the rest of FAANG will back it. It will be super technically correct but will include a cryptographic signature that only big tech companies can issue.
This is actually exactly what I asked for, thank you!!
https://cuelang.org/. I deal with a lot of k8s at work, and I've grown to hate YAML for complex configuration. The extra guardrails that Cue provides are hugely helpful for large projects.
Oh this! YAML was a terrible choice. And that's coming from someone who likes Python and prefers white spaces over brackets. YAML never clicked for me.
What you mean you can't easily tell what this is?
- foo: - - : - bar: baz: [ - - ]
Oh, this looks great!
I've been struggling between customize and helm. Neither seem to make k8s easier to work with.I have to try cuelang now. Something sensible without significant whitespace that confuses editors, variables without templating.
I'll have to see how it holds up with my projectsHmm, what alternative? XML :-)? People hate Grade DSL just for not being xml
ISO 216 paper sizes work like this: https://www.printed.com/blog/paper-size-guide/
It's so fucking neat and intuitive! How is it not used more???
sorry to tell you this bud...
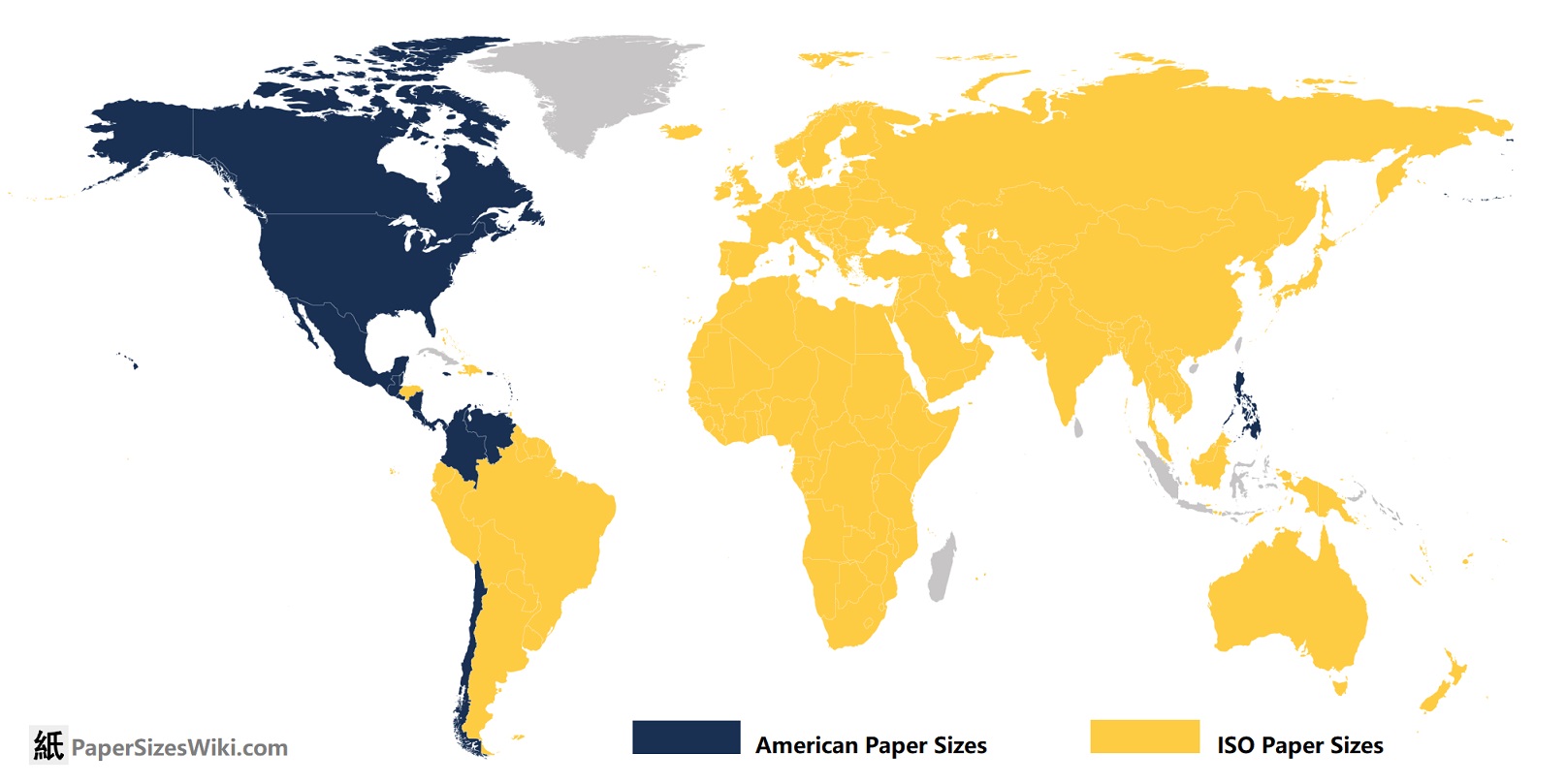
Clearly the rest of the world are communists! It's not us, it's you! I'm not crying you're crying! 😭😭😭
It's also worth noting that switching from ANSI to ISO 216 paper would not be a substantial physical undertaking, as the short-side of even-numbered ISO 216 paper (eg A2, A4, A6, etc) is narrower than for ANSI equivalents. And for the odd-numbered sizes, I've seen Tabloid-size printers in America which generously accommodate A3.
For comparison, the standard "Letter" paper size (aka ANSI A) is 8.5 inches by 11 inches. (note: I'm sticking with American units because I hope Americans read this). Whereas the similar A4 paper size is 8.3 inches by 11.7 inches. Unless you have the rare, oddball printer which takes paper long-edge first, this means all domestic and small-business printers could start printing A4 today.
In fact, for businesses with an excess stock of company-labeled #10 envelopes -- a common size of envelope, measuring 4.125 inches by 9.5 inches -- a sheet of A4 folded into thirds will still (just barely) fit. Although this would require precision folding, that's no problem for automated letter mailing systems. Note that the common #9 envelope (3.875 inches by 8.875 inches) used for return envelopes will not fit an A4 sheet folded in thirds. It would be advisable to switch entirely to A series paper and C series envelopes at the same time.
Confusingly, North America has an A-series of envelopes, which bear no relation to the ISO 216 paper series. Fortunately, the overlap is only for the less-common A2, A6, and A7.
TL;DR: bring reams of A4 to the USA and we can use it. And Tabloid-size printers often accept A3.
Presumably you could just buy that paper size? They're pretty similar sizes; printers all support both sizes. I've never had an issue printing a US Letter sized PDF (which I assume I have done).
Kind of weird that you guys stick to US Letter when switching would be zero effort. I guess to be fair there aren't really any practical benefits either.
Also, A4 simply has a better ratio than letter. Letter is too wide, making A4 better to hold and it fits more lines per page.
Most preschool kids know what an A4 sheet is. Not sure how it can be used more.
I wish standards were always open access. Not behind a 600 dollar paywall.
When it is paywalled I'm irritated it's even called a standard.
DP >> HDMI
GRPC for building APIs instead of REST. Type safety makes life easier
The biggest problems with gRPC are:
- Very complicated. Way more complexity than you want in most cases.
- Depends on HTTP 2. I've seen people who weren't even doing web stuff reach for gRPC, and now boom you have a web server in your stack for now reason. Compare to Thrift which properly separates out encodings, transports, etc.
- Doesn't work from the web. There are actually two modifications to gRPC to make it work on the web which means you have three different incompatible versions of gRPC with different feature sets. IIRC some of them require setting up complex proxies, some don't support streaming calls, ugh. Total mess.
Plain HTTP can be type safe. Just publish JSON schema or Typespec files or even use Protobuf.
Your concerns are all valid, but about 1 and 3 there are possible solutions. I'm using Rust+Tonic to build an API and that's eliminate the necessity of proxies and it's very simple to use.
I know that it don't solve all problems, but IMHO is a question of adoption. Easier
toldtools will be develop for it.Depends on HTTP 2.
Doesn’t work from the web.
Am I the only one who is weirded out? Requiring a web server for something and then requiring another server if you want it to actually work on the web?
How expensive do people want to make their deployments?
I mean, REST-ful JSON APIs can be perfectly type-safe, if their developers actually take care to make them that way. And the self-descriptive nature of JSON is arguably a benefit in really large public-facing APIs. But yeah, gRPC forces a certain amount of type-safety and version control, and gRPC with protobuf is SUCH a pleasure to work with.
Give it time, though, it's definitely gaining traction.
It's the recommended approach to replace WCF which was deprecated after .NET framework 4.8. My company is just now getting around to ripping out all their WCF stuff and putting in gRPC. REST interfaces were always a non-starter because of how "heavyweight" they were for our use case (data collection from industrial devices which are themselves data collectors).
I like the concept and I think the use case is almost covered by generating API client through generated OpenAPI spec.
It's needs a bit of setup but a client library can be built whenever a backend server is built.
The term open-standard does not cut it. People should start using "publicly available and sharable" instead (maybe there is a better name for it).
ISO standards for example are technically "open". But how relevant is that to a curious individual developer when anything you need to implement would require access to multiple "open" standards, each coming with a (monetary) price, with some extra shenanigans [archived] on top.
IETF standards however are actually truly open, as in publicly available and sharable.
how about FOSS, free and open-source standards /s
I wish there was a good open standard for task management or todo list.
I know there's todo.txt, but it lacks features like dependent tasks, and overall the plain text format limits features and implementations.
IRC.
Jabber.
IPFS.
I also pick this guy's IRC
Yes and RSS feeds.
Problem Details for HTTP APIs - I have to work and integrate with a lot of different APIs and different kinda implementations of error handling. Everyone seems to be inventing their own flavor of returning errors.
My life would be so much easier if everyone just used some 'global unified' way to returning errors, all in the same way
That would be nice. I have implemented this in the past but never once encountered an API that used it.
Best is when the API doesn't match a PDF and says "500: Internal Error"
Saving...
I made my first API at work last year (still making) and always saw myself looking for input on making a consistent way to return errors, with no useful input from the senior programmers or the API users. This is my second biggest problem, the first being variable and function names of course.
If I were to do anything related to HTTP, I now have something to look at.
TOML instead of YAML or JSON for configuration.
YAML is complex and has security concerns most people are not aware of.
JSON works, but the block quoting and indenting is a lot of noise for a simple category key value format.
YAML is complex and has security concerns most people are not aware of.
YAML is racist to Norwegians.
If you have something like
country: NO(NO = Norway), YAML will turn that intocountry: False. Why? Implicit casting. There are a bunch of truthy strings that'll be cast automagically.TOML is not a very good format IMO. It's fine for very simple config structures, but as soon as you have any level of nesting at all it becomes an unobvious mess. Worse than YAML even.
What is this even?
[[fruits]] name = "apple" [fruits.physical] color = "red" shape = "round" [[fruits.varieties]] name = "red delicious" [[fruits.varieties]] name = "granny smith" [[fruits]] name = "banana" [[fruits.varieties]] name = "plantain"That's an example from the docs, and I have literally no idea what structure it makes. Compare to the JSON which is far more obvious:
{ "fruits": [ { "name": "apple", "physical": { "color": "red", "shape": "round" }, "varieties": [ { "name": "red delicious" }, { "name": "granny smith" } ] }, { "name": "banana", "varieties": [ { "name": "plantain" } ] } ] }The fact that they have to explain the structure by showing you the corresponding JSON says a lot.
JSON5 is much better IMO. Unfortunately it isn't as popular and doesn't have as much ecosystem support.
JSON5
Nice. I mostly use Qt JSON and upon reading the spec, I see at least a few things I would want to have out of this, even when using it for machine-machine communication
You're using a purposely convoluted example from the spec. And I think it shows exactly how TOML is better than JSON for creating config files.
The TOML file is a lot easier to scan than the hopelessly messy json file. The mix of indentation and symbols used in JSON really does not do well in bigger configuration files.
People bitch about YAML but for me it's still the preferred one just because the others suck more.
TOML like said is fine for simple things but as soon as you get a bit more complex it's messy and unwieldy. And JSON is fine to operate on but for a config? It's a mess. It's harder to type and read for something like a config file.
Heck, I'm not even sold on the S-expressions compared to yaml yet. But then, I deal with so much with all of these formats that I simply still prefer YAML for readability and ease of use (compared to the others.)
I don't use XMPP but it seems like such a no-brainer
Not matrix? XMPP is a good idea, but the wildly different levels of support among clients cause problems even back in its heyday Matrix solves some of that, fully encrypted, chat history stored on the server in encrypted form, supports gateways to other services.
Those problems you speak of about XMPP are not really a concern anymore and haven't been for a while.
Matrix on the other hand is very difficult to implement, and currently there's only one (maybe two?) viable implementation choices. It is way over complicated, resource intensive, and has privacy issues.
Definitely not matrix.
Alright, but seriously: IPv6.
(Holocene or) Human Era calendar
That would represent all human history as one.
And also, the Dekatrian calendar
Where we would have a less broken, more regular, year calendar that is almost align with the moon cycle.

Oh many years ago in school I created something like that for an arts/creative writing project once, a calendar with 12, 30 day month based on sailor moon. Having it based on a magical girl manga gave me the freedom to declare the rest of the days to "days of evil" Was a fun project because I created a whole religion around it. 😁
That sounds interesting, would most likely not be very popular with lots of people and a pain in the butt to implement but interesting.
There's a cool video from In a Nutshell about it some years ago.
Org-mode is like md but has tables and more. Emacs will even run computation as a party of interpretation. GitHub accepts it in place of markdown.
Would you say it's worth considering in place of markdown for a non-emacs user? (I am curious to try emacs but I may not get to it anytime soon)
org-mode is awesome for many reasons, but the similarities/overlap with markdown are an incidental benefit. I wouldn't learn org-mode for that reason, however there are many other good ones that make it worthwhile. I've been using it for years for my own project management, tasks tracking, notes and many other things - it's one of those rare tools that can do many things incredibly well.
About s-expressions, what i read about it: https://web.archive.org/web/20120206034439/https://shinkirou.org/blog/2010/06/s-expressions-the-fat-free-alternative-to-json/
Seems rather niche, for non-key-value-pair data structures (aren't no-sql databases good for that?), considering that lightweight markup fulfills that role for readable document source.
The appeal for json and yaml is readability, and partially ease of parsing. I say s-expressions win over both in both aspects.
Can you please expand on your references to no-sql and your reference to "lightweight markup"? I don't quite understand what you meant there.
S-expressions are basically directly writing the AST a compiler would normally generate. They can be extremely flexible. M-expressions were supposed to be programming part of Lisp, and S-expressions the data part. Lisp programmers noticed that code is just another kind of data to be manipulated and then only used S-expressions.
Logo is arguably a Lisp with M-expressions. But whatever niche Logo had is taken by Python now.
XMPP, RSS, ...
For RSS I honestly don't see a point, at least for me. What's the use for having update feeds in a unified format when I still have to go to each fucking site to view the full text? I completely see the point of RSS when all I need is in the feed. But I hate going from different UI to different UI to get the full content. I want something like inoreader.com for self-hosting.
RSS works great for me though.
I have an app on my not-so-smart phone to read news when commuting. It is not a long journey so I just want to have a quick glance at the headlines and read the actual articles that I want to. There are only 6 sites that I am interested, but still will take quite some work to crawl from the proper websites. RSS in turn is unified so I don't need to worry about their website layouts, formats, etc. It also gives me an URL to the actual content which I can use readability/reader mode library to parse and further reduce unnecessary contents.
Quite the opposite, I hope more informational sites offer/keep RSS! (Some removed RSS typically after a revamp, design change)
What's the use for having update feeds in a unified format when I still have to go to each fucking site to view the full text
This has nothing to do with RSS, it is the author's choice. It's like someone who posts links to their articles on Twitter / Facebook / Reddit, same thing. The platform doesn't prevent you from putting the entire content there, and in fact, many do, especially with RSS.
One benefit of RSS though is that because it is an open protocol, the problem you mention already has solutions, which auto fetch the articles for you. That wouldn't be possible without an open protocol like RSS
Moreover, I'd argue even with that, RSS is still a huge plus. To have all your content's headlines in one UI, and potentially you can filter or sort them however you want, that's pretty awesome.
XMPP is not a good protocol though. There's a reason nobody uses it anymore.
I think it's going to be interesting when the EU tries to enforce interoperability between the major messaging platforms. What are they going to do? They have some ridiculous targets like interoperable end-to-end encrypted group video calls in 5 years!
There's a reason nobody uses it anymore.
I and many others use it! And Google, meta, etc. Have used it but decided to lock it down.
Yes you're right, there's a reason people don't use it as much, which is because these corporations embraced it, dominated it, then extinguished it.
But XMPP is honestly my favorite comm protocol and the most impressive imo.
Not sure if it counts, but the terminal world being a place where many applications do so many different things but are interoperable, is amazing. I guess that would be the POSIX standard?
AV1 video codec !
I'll add JXL if we're doing codecs
Is ipfs usage growing? Stagnant? No idea... Diatributed serving of content seems great
I never really quite understood IPFS and why it gets used where I see it today. What problem is it solving?
file sharing between planets, obviously /s
IPFS would replace Content Delivery Networks in present day.
It would also allow you to host software and other content from your own network again without the constraints modern Internet Service Providers pose on you to limit your self-hosting capabilities.
If applications are built for it, it could serve as live storage for your applications too.
We ran ipf-search. In one of the experiments we could show that a distributed search index on ipfs-search, accessible through JavaScript is likely feasible with the necessary research. Parts of the index would automatically be hosted by clients who used the index thus creating a fairly resilient system.
Too bad IPFS couldn't get over the technical hurdles of limiting connection setup time. We could get a fast (ElasticSearch based) index running and hosted over common web technologies, but fetching content from IPFS directly was generally rather slow.
Yeah it's basically a benevolent-store-static-data, where static is you cannot change it (or you have to upload new data and make a new link to it).
Cool name though.
The semantic web and social linked data. We could have applications share data without depending on big tech, but rather based on application standards.
It can be used today and gains traction but I wouldn't mind it going faster. Especially the interoperable personal app space could use some love and attention.
Like with the Solid Project ?
Exactly. The Semantic Web is broader than Solid but Solid is great for personal apps.
Say you buy a smartphone. The specifications of the smartphone likely belong elsewhere than in a Solid Personal Online Datastore, but they can be pulled in from semantic data on the product website. Your own proof of purchase is a great candidate for a Solid POD, as is the trace of any repairs made to it.
These technologies are great to cross the barriers between applications. If we'd embrace this, it would be trivial to find the screen protector matching your exact smartphone because we'd have an identifier to discover its type and specifications. Heck, any product search would be easier if you could combine sources and compare with what you already have.
The sharing tech exists. Building apps works also. Interpreting the information without building a dedicated interface seems lacking for laymen.
Unicode editors for notes/todo formats, making markup unnecessary.
Does unicode have bold/italics/underline/headings/tables/...etc.? Isn't that outside of its intended goal? If not, how is markup unnecessary?
Does unicode have bold/italics/underline/headings/tables/
Yes, and even 𝓈𝓉𝓊𝒻𝒻 𝕝𝕚𝕜𝕖 🅣🅷🅘🆂. And table lines & edges & co. are even already in ASCII.
Isn't that outside of its intended goal?
🤷<- this emoji has at least 6 color variants and 3 genders.
If not, how is markup unnecessary?
Because the editor could place a 𝗯𝗼𝗹𝗱 instead of a **bold**, which is a best-case-scenario with markdown support btw. And i just had to escspe the stars, which is a problem that native unicode doesn't pose.
SqLite for office formats.
I'm not quite following this. Can you please elaborate?
I read this somewhere. Since i didn't find it anymore and don't remember all the advantages aside from concurrence (don't have to unpack a zip archive) i asked chatgpt:
Using SQLite instead of ZIP for office formats can offer several advantages, particularly in terms of data management, performance, and functionality. Here are some key benefits:
- Structured Data Storage: SQLite is a relational database management system, which means it can store data in a structured format with relationships between different data entities. This allows for more complex data queries and relationships compared to a flat ZIP file structure.
Query Capabilities: With SQLite, you can use SQL queries to retrieve and manipulate data efficiently. This is particularly useful for applications that require complex data retrieval, filtering, and aggregation, which would be cumbersome with a ZIP file.
Integration with Other Tools: SQLite can be easily integrated with various programming languages and tools, making it a versatile choice for applications that require data storage and manipulation.
- Concurrency: SQLite supports multiple readers and a single writer, allowing for better concurrency when accessing and modifying data. This can be beneficial in collaborative environments where multiple users may need to access or update the data simultaneously.
- Data Integrity: SQLite provides features like transactions, which ensure that a series of operations either complete successfully or leave the database unchanged. This helps maintain data integrity, especially in scenarios where multiple operations are performed.
- Ease of Updates: Updating specific pieces of data in an SQLite database can be more efficient than modifying a ZIP file, which may require decompressing, altering, and recompressing the entire file.
- Reduced File Size: While ZIP files compress data, SQLite can store data in a more compact format, especially for structured data. This can lead to smaller file sizes for certain types of data. Built-in Data Types: SQLite supports various data types (e.g., INTEGER, TEXT, BLOB), which can be beneficial for storing different kinds of data in a more organized manner compared to the generic binary format of ZIP files.
- Versioning and History: SQLite can be used to implement versioning and history tracking for documents, allowing users to maintain a history of changes and revert to previous versions if necessary.
I put related points together. One point was moot, removed.
- Structured Data Storage: SQLite is a relational database management system, which means it can store data in a structured format with relationships between different data entities. This allows for more complex data queries and relationships compared to a flat ZIP file structure.
djot for text markup. It addresses a lot of the issues in Common mark (and of course far more of the issues of Markdown).
I like the Doxygen's implementation and extension of Markdown. Pair it with PlantUML and you have something worth being a standard.
NNTPS
I'd like something akin to XML DOM for config files, but not XML.
The one benefit of binary config (like the Windows Registry) is that you can make a change programmatically without too many hoops. With text files, you have a couple of choices for programmatic changes:
- Don't
- Parse it, make the change, and rewrite it (clobbering comments and whitespace that the user setup; IIRC, npm does this)
- Have some kind of block that says "things below this line were automatically set and shouldn't be touched" (Klipper does this)
- Have a parser that understands the whole structure, including whitespace and comments, and provides an interface for modifying things in place without changing anything around it (XML DOM)
That last one probably exists for very specific formats for very specific languages, but it's not common. It's a little more cumbersome to use as a programmer--anyone who has worked with XML DOM will attest to that--but it's a lot nicer for end users.
Have you heard about KDL?