if you could standardise a file format for a specific task what would you pick and why
if you could standardise a file format for a specific task what would you pick and why
if you could pick a standard format for a purpose what would it be and why?
e.g. flac for lossless audio because...
(yes you can add new categories)
summary:
- photos .jxl
- open domain image data .exr
- videos .av1
- lossless audio .flac
- lossy audio .opus
- subtitles srt/ass
- fonts .otf
- container mkv (doesnt contain .jxl)
- plain text utf-8 (many also say markup but disagree on the implementation)
- documents .odt
- archive files (this one is causing a bloodbath so i picked randomly) .tar.zst
- configuration files toml
- typesetting typst
- interchange format .ora
- models .gltf / .glb
- daw session files .dawproject
- otdr measurement results .xml
Just going to leave this xkcd comic here.
Yes, you already know what it is.
One could say it is the standard comic for these kinds of discussions.
There are too many of these comics, I'll make one to be the true comic response and unite all the different competing standards
🪛
Open Document Standard (.odt) for all documents. In all public institutions (it's already a NATO standard for documents).
Because the Microsoft Word ones (.doc, .docx) are unusable outside the Microsoft Office ecosystem. I feel outraged every time I need to edit .docx file because it breaks the layout easily. And some older .doc files cannot even work with Microsoft Word.
Actually, IMHO, there should be some better alternative to .odt as well. Something more out of a declarative/scripted fashion like LaTeX but still WYSIWYG. LaTeX (and XeTeX, for my use cases) is too messy for me to work with, especially when a package is Byzantine. And it can be non-reproducible if I share/reuse the same document somewhere else.
Something has to be made with document files.
Markdown, asciidoc, restructuredtext are kinda like simple alternatives to LaTeX
There is also https://github.com/typst/typst/
It is unbelievable we do not have standard document format.
What's messed up is that, technically, we do. Originally, OpenDocument was the ISO standard document format. But then, baffling everyone, Microsoft got the ISO to also have
.docxas an ISO standard. So now we have 2 competing document standards, the second of which is simply worse.That's awful, we should design something that covers both use cases!
I was too young to use it in any serious context, but I kinda dig how WordPerfect does formatting. It is hidden by default, but you can show them and manipulate them as needed.
It might already be a thing, but I am imagining a LaTeX-based standard for document formatting would do well with a WYSIWYG editor that would hide the complexity by default, but is available for those who need to manipulate it.
There are programs (LyX, TexMacs) that implement WYSIWYG for LaTeX, TexMacs is exceptionally good. I don't know about the standards, though.
Another problem with LaTeX and most of the other document formats is that they are so bloated and depend on many other tasks that it is hardly possible to embed the tool into a larger document. That's a bit of criticism for UNIX design philosophy, as well. And LaTeX code is especially hard to make portable.
There used to be a similar situation with PDFs, it was really hard to display a PDF embedded in application. Finally, Firefox pdf.js came in and solved that issue.
The only embedded and easy-to-implement standard that describes a 'document' is HTML, for now (with Javascript for scripting). Only that it's not aware of page layout. If only there's an extension standard that could make a HTML page into a document...
Bro, trying to give padding in Ms word, when you know... YOU KNOOOOW... they can convert to html. It drives me up the wall.
And don't get me started on excel.
Kill em all, I say.
This is the kind of thing i think about all the time so i have a few.
- Archive files:
.tar.zst- Produces better compression ratios than the DEFLATE compression algorithm (used by
.zipandgzip/.gz) and does so faster. - By separating the jobs of archiving (
.tar), compressing (.zst), and (if you so choose) encrypting (.gpg),.tar.zstfollows the Unix philosophy of "Make each program do one thing well.". .tar.xzis also very good and seems more popular (probably since it was released 6 years earlier in 2009), but, when tuned to it's maximum compression level,.tar.zstcan achieve a compression ratio pretty close to LZMA (used by.tar.xzand.7z) and do it faster^1.zstd and xz trade blows in their compression ratio. Recompressing all packages to zstd with our options yields a total ~0.8% increase in package size on all of our packages combined, but the decompression time for all packages saw a ~1300% speedup.
- Produces better compression ratios than the DEFLATE compression algorithm (used by
- Image files:
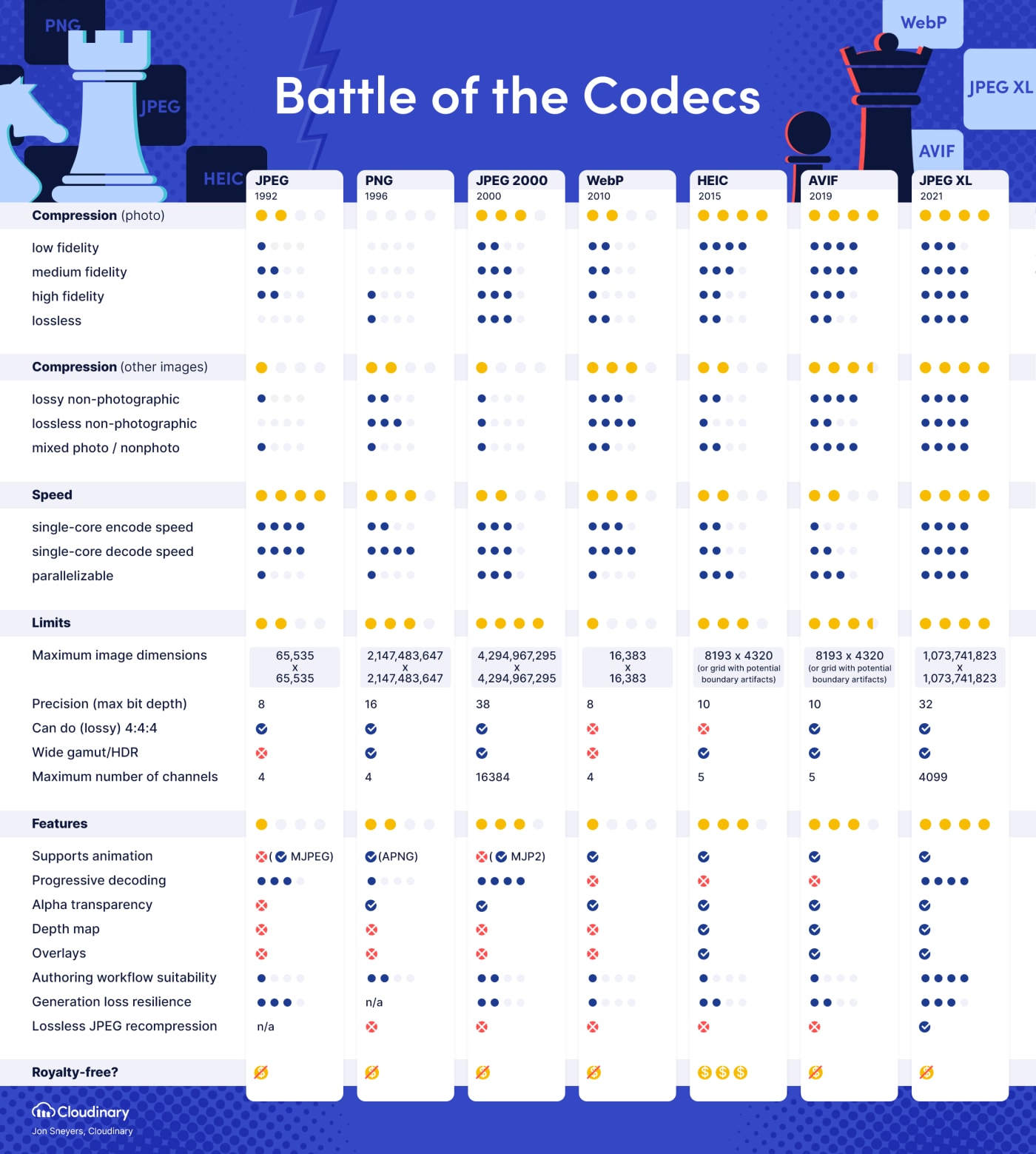
JPEG XL/.jxl- "Why JPEG XL"
- Free and open format.
- Can handle lossy images, lossless images, images with transparency, images with layers, and animated images, giving it the potential of being a universal image format.
- Much better quality and compression efficiency than current lossy and lossless image formats (
.jpeg,.png,.gif). - Produces much smaller files for lossless images than AVIF^2
- Supports much larger resolutions than AVIF's 9-megapixel limit (important for lossless images).
- Supports up to 24-bit color depth, much more than AVIF's 12-bit color depth limit (which, to be fair, is probably good enough).
- Videos (Codec):
AV1- Free and open format.
- Much more efficient than x264 (used by
.mp4) and VP9^3.
- Documents:
OpenDocument / ODF / .odt- @[email protected] says it best here.
.odtis simply a better standard than.docx.
it’s already a NATO standard for documents Because the Microsoft Word ones (.doc, .docx) are unusable outside the Microsoft Office ecosystem. I feel outraged every time I need to edit .docx file because it breaks the layout easily. And some older .doc files cannot even work with Microsoft Word.
- @[email protected] says it best here.
- By separating the jobs of archiving (
.tar), compressing (.zst), and (if you so choose) encrypting (.gpg),.tar.zstfollows the Unix philosophy of "Make each program do one thing well.".
wait so does it do all of those things?
So there's a tool called tar that creates an archive (a
.tarfile. Then theres a tool called zstd that can be used to compress files, including.tarfiles, which then becomes a.tar.zstfile. And then you can encrypt your.tar.zstfile using a tool called gpg, which would leave you with an encrypted, compressed.tar.zst.gpgarchive.Now, most people aren't doing everything in the terminal, so the process for most people would be pretty much the same as creating a ZIP archive.
- By separating the jobs of archiving (
By separating the jobs of archiving (.tar), compressing (.zst), and (if you so choose) encrypting (.gpg), .tar.zst follows the Unix philosophy of “Make each program do one thing well.”.
The problem here being that GnuPG does nothing really well.
Videos (Codec): AV1
- Much more efficient than x264 (used by .mp4) and VP9[3].
AV1 is also much younger than H264 (AV1 is a specification, x264 is an implementation), and only recently have software-encoders become somewhat viable; a more apt comparison would have been AV1 to HEVC, though the latter is also somewhat old nowadays but still a competitive codec. Unfortunately currently there aren't many options to use AV1 in a very meaningful way; you can encode your own media with it, but that's about it; you can stream to YouTube, but YouTube will recode to another codec.
The problem here being that GnuPG does nothing really well.
Could you elaborate? I've never had any issues with gpg before and curious what people are having issues with.
Unfortunately currently there aren’t many options to use AV1 in a very meaningful way; you can encode your own media with it, but that’s about it; you can stream to YouTube, but YouTube will recode to another codec.
AV1 has almost full browser support (iirc) and companies like YouTube, Netflix, and Meta have started moving over to AV1 from VP9 (since AV1 is the successor to VP9). But you're right, it's still working on adoption, but this is moreso just my dreamworld than it is a prediction for future standardization.
.odt is simply a better standard than .docx.
No surprise, since OOXML is barely even a standard.
I get better compression ratio with xz than zstd, both at highest. When building an Ubuntu squashFS
Zstd is way faster though
is av1 lossy
AV1 can do lossy video as well as lossless video.
Damn didn't realize that JXL was such a big deal. That whole JPEG recompression actually seems pretty damn cool as well. There was some noise about GNOME starting to make use of JXL in their ecosystem too...
- Archive files:
zip or 7z for compressed archives. I hate that for some reason rar has become the defacto standard for piracy. It's just so bad.
The other day I saw a tar.gz containing a multipart-rar which contained an iso which contained a compressed bin file with an exe to decompress it. Soooo unnecessary.
Edit: And the decompressed game of course has all of its compressed assets in renamed zip files.
A .tarducken, if you will.
Ziptarar?
It was originally rar because it’s so easy to separate into multiple files. Now you can do that in other formats, but the legacy has stuck.
Not just that. RAR also has recovery records.
.tar.zstdall the way IMO. I've almost entirely switched to archiving with zstd, it's a fantastic format..tar.xz masterrace
This comment didn't age well.
Literally any file format except PDF for documents that need to be edited. Fuck Adobe and fuck Acrobat
Isn't the point of PDF that it can't (or, perhaps more accurately, shouldn't) be edited after the fact? It's supposed to be immutable.
Unless you have explicitly digitally-signed the PDF, it's not immutable. It's maybe more-annoying to modify, but one shouldn't rely on that.
And there are ways to digitally-sign everything, though not all viewing software has incorporated signature verification.
I’m not sure if they were ever designed to be immutable, but that’s what a lot of people use it for because it’s harder to edit them. But there are programs that can edit PDFs. The main issue is I’m not aware of any free ones, and a lot of the alternatives don’t work as well as Adobe Acrobat which I hate! It’s always annoying at work when someone gets sent a document that they’re expected to edit and they don’t have an Acrobat license!
No, it's too preserve formatting when distributed. Editing is absolutely possible, always were, it's just annoying to parse the structure when trying to preserve the format as you make changes
No, although there's probably a culture or convention around that.
Originally the idea was that it's a format which can contain fonts and other things so it will be rendered the same way on different devices even if those devices don't have those fonts installed. The only reason it's not commonly editable that I'm aware of is that it's a fairly arcane proprietary spec.
Now we have the openspec odt which can embed all the things, so pdf editing just doesn't really seem to have any support.
The established conventions around pdfs do kind of amaze me. Like contracts get emailed for printing & signing all the time. In many cases it would be trivial to edit the pdf and return your edited copy which the author is unlikely to ever read.
Why would you use acrobat? I haven't used it in many years and use PDFs all the time
Acrobat Reader is actually great for filling out forms.
Even if the "pdf" is actually just a potato quality photo of what was at some time a form, you can still fill it out in Acrobat Reader.
Generally in windows I prefer sumatra pdf as a reader, but I keep acrobat around for this purpose.
Ogg Opus for all lossy audio compression (mp3 needs to die)
7z or tar.zst for general purpose compression (zip and rar need to die)
The existence of zip, and especially rar files, actually hurts me. It's slow, it's insecure, and the compression is from the jurassic era. We can do better
@dinckelman @Supermariofan67 I think you mean unsecure. It doesn't feel unsure of itself. 😁
why does zip and rar need to die
Zip has terrible compression ratio compared to modern formats, it's also a mess of different partially incompatible implementations by different software, and also doesn't enforce utf8 or any standard for that matter for filenames, leading to garbled names when extracting old files. Its encryption is vulnerable to a known-plaintext attack and its key-derivation function is very easy to brute force.
Rar is proprietary. That alone is reason enough not to use it. It's also very slow.
How about tar.gz? How does gzip compare to zstd?
Both slower and worse at compression at all its levels.
why does ml3 need todie
It's a 30 year old format, and large amounts of research and innovation in lossy audio compression have occurred since then. Opus can achieve better quality in like 40% the bitrate. Also, the format is, much like zip, a mess of partially broken implementations in the early days (although now everyone uses LAME so not as big of a deal). Its container/stream format is very messy too. Also no native tag format so it needs ID3 tags which don't enforce any standardized text encoding.
How about xz compared to zstd?
At both algorithms' highest levels, xz seems to be on average a few percent better at compression ratio, but zstd is a bit faster at compression and much much faster at decompression. So if your goal is to compress as much as possible without regard to speed at all,
xz -9is better, but if you want compression that is almost as good but faster,zstd --long -19is the way to goAt the lower compression presets, zstd is both faster and compresses better
JPEG-XL for rasterized images.
I agree.
I especially love that it addresses the biggest pitfall of the typical "fancy new format does things better than the one we're already using" transition, in that it's specifically engineered to make migration easier, by allowing a lossless conversion from the dominant format.
Never heard of that, thanks for bringing it to my attention!
I don't know what to pick, but something else than PDF for the task of transferring documents between multiple systems. And yes, I know, PDF has it's strengths and there's a reason why it's so widely used, but it doesn't mean I have to like it.
Additionally all proprietary formats, specially ones who have gained enough users so that they're treated like a standard or requirement if you want to work with X.
oh it's x, not x... i hate our timeline
I would be fine with PDFs exactly the same except Adobe doesn't exist and neither does Acrobat.
When PDF was introduced it made these things so much better than they were before that I'll probably remain grateful for PDF forever and always forgive it all its flaws.
I would be fine with PDFs exactly the same except Adobe doesn't exist and neither does Acrobat.
Resume information. There have been several attempts, but none have become an accepted standard.
When I was a consultant, this was the one standard I longed for the most. A data file where I could put all of my information, and then filter and format it for each application. But ultimately, I wanted to be able to submit the information in a standardised format - without having to re-enter it endlessly into crappy web forms.
I think things have gotten better today, but at the cost of a reliance on a monopoly (LinkedIn). And I'm not still in that sort of job market. But I think that desire was so strong it'll last me until I'm in my grave.
SQLite for all “I’m going to write my own binary format because I is haxor” jobs.
There are some specific cases where SQLite isn’t appropriate (streaming). But broadly it fits in 99% of cases.
To chase this - converting to json or another standardized format in every single case where someone is tempted to write their own custom parser. Never write custom parsers kids, they're an absolutely horrible time-suck and you'll be fixing them quite literally forever as you discover new and interesting ways for your input data to break them.
Edit: it doesn't have to be json, I really don't care what format you use, just pick an existing data format that uses a robust, thoroughly tested, parser.
To add to that. Configuration file formats...just pick a standard one, do not write your own.
And while we are at it, if there is even a remote chance that you have a "we will do everything declaratively" idea, just use an existing programming language for your file format instead of painfully growing some home-grown add-ons to your declarative format over the next decade or two because you were wrong about only needing a declarative format.
Also parquet if the data aren't mutated much.
give me a category please
I’ll take “what’s that file format for $300 please”
Yeah, what was it? If office formats used sqlite instead of zip?
Data output from manufacturing equipment. Just pick a standard. JSON works. TOML / YAML if you need to write as you go. Stop creating your own format that’s 80% JSON anyways.
JSON is nicer for some things, and YAML is nicer for others. It'd be nice if more apps would let you use whichever you prefer. The data can be represented in either, so let me choose.
KDL enters the chat
I'd like an update to the epub ebook format that leverages zstd compression and jpeg-xl. You'd see much better decompression performance (especially for very large books,) smaller file sizes and/or better image quality. I've been toying with the idea of implementing this as a .zpub book format and plugin for KOReader but haven't written any code for it yet.
XML for machine-readable data because I live to cause chaosEither markdown or Org for human-readable text-only documents. MS Office formats and the way they are handled have been a mess since the 2007 -x versions were introduced, and those and Open Document formats are way too bloated for when you only want to share a presentable text file.
While we're at it, standardize the fucking markdown syntax! I still have nightmares about Reddit's degenerate four-space-indent code blocks.
Man, I'd love if markdown was more widely used, it's pretty much the perfect format for everything I do
Markdown, CommonMark, .rst formats are good for printing basic rich text for technical documentation and so on, when text styling is made by an external application and you don't care about reproducible layout.
But you also want to make custom styles (font size, text alignment, colours), page layout (paper format, margin size, etc.) and make sure your document is reproducible across multiple processing applications, that the layout doesn't break, authoring tools, maybe even some version control, etc. This is when it strikes you bad.
Markdown misses checkboxes anywhere, especially in tables.
But markdown is just good. It's just writing text as normal basically
You can convert Markdown to a number of formats with pandoc, if you want to author in Markdown and just distribute in some other format.
Not going to work if you need to collaborate with other people, though.
TOML for configuration files
100% this. Much more readable than JSON, YAML or other custom formats.
I am surprised no one mentioned HCL yet. It's just as sane as toml but it is also properly nestable, like yaml, while being easily parsable and formattable. I wish it was used more as a config language.
UTF-8 for plain text, trying to figure out the encoding, especially with older files/equipment/software is super annoying.
.gltf/.glb for models. It's way less of a headache than .obj and .dae, while also being way more feature rich than either.
Either that or .blend, because some things other than blender already support it and it'd make my life so much easier.
USD is basically this, and is supported everywhere, give it a look!
USD is more for scenes than models. It's meant primarily for stuff like 3dsmax and blender, and is far more complex than gltf.
It's also not really supported everywhere. Pretty much every game engine lacks support for USD, while most (except unity for some reason) have at least some gltf support.
USD is also, at least as far as I'm concerned, dead in the water. I have never encountered a single USD file in the wild, though that might just be because I mainly only work in blender and godot.
I'm not against USD, and I'd love to see it get some more love, but it serves a different purpose than gltf.
matroska for media, we already have MKA for audio and MKV for video. An image container would be good too.
mp4 is more prone to data loss and slower to parse, while also being less flexible, despite this it seems to be a sort of pseudo standard.
(MP4, M4A, HEIF formats like heic, avif)
wait why not av4 or jpegxl
those are media formats, not containers.
A mp4 file contains media in, for example, h264 and AAC codec, which is the combined for playback. It is not a codec itself.
im compiling summarised list in body, what do i put this under and what file extensions
Markdown for all rich text that doesn't need super fancy shit like latex
Definitely FLAC for audio because it's lossless, if you record from a high fidelity source....
exFAT for external hard drives and SD cards because both Windows and Mac can read and write to it as well as Linux. And you don't have the permission pain....
What permission pain?
If you were to format the drive with extra and then copy something to it from Linux - if you try open it on another Linux machine (eg you distro hop after this event) it won't open the file because your aren't the owner.
Then you have to jump though hoops trying to make yourself the owner just so you can open your own file.
I learnt this the hard way so I just use exFAT and it all works.
JPEG XL for images because it compresses better than JPEG, PNG and WEBP most of the time.
XZ because it theoretically offers the highest compression ratio in most circumstances, and long decompression time isn't really an issue when the alternative is downloading a larger file over a slow connection.
Config files stored as serialized data structures instead of in plain text. This speeds up read times and removes the possibility of syntax or type errors. Also, fuck JSON.
I wish there were a good format for typesetting. Docx is closed and inflexible. LaTeX is unreadable, inefficient to type and hard to learn due to the inconsistencies that arise from its reliance on third-party packages and its lack of guidelines for their design.
Typst for typesetting. Definitely underrated.
Some sort of machine-readable format for invoices and documents with related purposes (offers, bills of delivery, receipts,...) would be useful to get rid of some more of the informal paper or PDF human-readable documents we still use a lot. Ideally something JSON-based, perhaps with a cryptographic signature and encryption layer around it.
This one exists. SEPA or ISO20022. Encryption/signing isn't included in the format, it's managed on transfer layer, but that's pretty much the standard every business around here works and many don't even accept PDFs or other human-readable documents anymore if you want to get your money.
i hate to be that guy, but pick the right tool for the right job. use markdown for a readme and latex for a research paper. you dont need to create 'the ultimate file format' that can do both, but worse and less compatible
I agree with your assertion that there isn't a perfect format. But the example you gave - markdown vs latex has a counter example - org mode. It can be used for both purposes and a load of others. Matroska container is similarly versatile. They are examples that carefully designed formats can reach a high level of versatility, though they may never become the perfect solution.
.dontuse for snaps
i'd like there to be a way to standardise midi info in plugins for music
Is ogg lossless?
It's a container format that can hold either lossless or lossy codecs
Yes, if you encode with a lossless codec like FLAC or OggPCM and not Vorbis or Opus.
Something for I/Q recordings. But I don't know what would do it. Currently the most supported format seems to be s16be WAV, but there's different formats, bit depths and encodings. I've seen .iq, .sdriq, .sdr, .raw, .wav. Then there's different bit depths and encodings: u8, s8, s16be, s16le, f32,... Also there's different ways metadata like center frequency is stored.
what is this
God damnit. I wrote an answer and it disappeared a while after pressing reply. I am lazy to rewrite it and my eyes are sore.
Anyway, I am too dumb to actually understand I/Q samples. It stands for In-Phase and Quadrature, they are 90° out of phase from each other. That's somehow used to reconstruct a signal. It's used in different areas. For me it's useful to record raw RF signals from software defined radio (SDR).
For example, with older, less secure systems, you could record signal from someone's car keyfob, then use a Tx-capable SDR to replay it later. Ta-da! Replay attack. You unlocked someone's car.
In a better way, you could record raw signal from a satellite to later demodulate and decode it, if your computer isn't powerful enough to do it in real-time.If you want an example, you can download DAB+ radio signal recording here: https://www.sigidwiki.com/wiki/DAB%2B and then replay it in Welle.io (available as Appimage) if it's in compatible format. I haven't tested it.
Some new format for DAW session files that is compatible with all DAWs. I believe ardour can import protools files but I bet a lot. Of work went into that.
Nice, hadn't seen this before. From the looks of the Ardour forum there is nobody currently looking at implementing the forum but they seem open to it. I would contribute but I only know python so probably not much use. I could write a ardour-dawproject translator in python but seems a bit pointless if someone goes and creates a proper implementation at some point anyway
.mom for ascii written Your Mom jokes.
OTDR measurement results in like XML or whatever open self documenting format, just not SOR. Or even just in actual standards compliant SOR, if that's all I can get.
i dont understand any if the acrobyms
except XML xD
OTDR: Optical Time Domain Reflectometry
SOR: Standard OTDR Record
XML: Extensible Markup Language.sor files are a mess, poorly standardized, too restrictive as a format, and every manufacturer makes their own proprietary extensions.
.nix for software packaging.
whats that and why nkt flatpak
MKV It supports high-quality video and audio codecs, allowing for lossless compression and high-definition content. Also MKV supports chapter and menu functionality, making it suitable to rip DVD to MKV and store DVDs and Blu-ray discs.
blk.dat for all stored human labor, to eliminate the Cantillon effect.
192 kHz for music.
The CD was the worst thing to happen in the history of audio. 44 (or 48) kHz is awful, and it is still prevalent. It would be better to wait a few more years and have better quality.
Why? What reason could there possibly be to store frequencies as high as 96 kHz? The limit of human hearing is 20 kHz, hence why 44.1 and 48 kHz sample rates are used
On top of that, 20 kHz is quite the theoretical upper limit.
Most people, be it due to aging (affects all of us) or due to behaviour (some way more than others), can't hear that far up anyway. Most people would be suprised how high up even e.g. 17 kHz is. Sounds a lot closer to very high pitched "hissing" or "shimmer", not something that's considered "tonal".
So yeah, saying "oh no, let me have my precious 30 kHz" really is questionable.
At least when it comes to listening to finished music files. The validity of higher sampling frequencies during various stages in the audio production process is a different, way less questionable topic,
That is not what 96khz means. It doesn't just mean it can store frequencies up to that frequency, it means that there are 96,000 samples every second, so you capture more detail in the waveform.
Having said that I'll give anyone £1m if they can tell the difference between 48khz and 96khz. 96khz and 192khz should absolutely be used for capture but are absolutely not needed for playback.
I assume you're gonna back that up with a double blind ABX test?
44 KHz wasn't chosen randomly. It is based in the range of frequencies that humans can hear (20Hz to 20KHz) and the fact that a periodic waveform can be exactly rebuild as the original (in terms of frequency) when sampling rate is al least twice the bandwidth. So, if it is sampled at 44KHz you can get all components up to 22 KHz whics is more that we can hear.
this is wrong. the first thing done before playing one of those files is running ithe audio through a low pass filter that removes any extra frequencies 192khz captures. because most speakers can't play them, and in fact would distort the rest of the sound (due to badly recreating them, resulting in aliasing).
192khz has a place, and it's called the recording studio. It's only useful when handling intermediate products in mixing and mastering. Once that is done, only the audible portion is needed. The inaudible stuff can either be removed beforehand, saving storage space, or distributed (as 192khz files) and your player will remove them for you before playback
.exe to .sh low key turn all windows machines to Linux machines
You're comparing compiled executables to scripts, it's apples and oranges.
I, for one, label my apple crates as oranges.
winebin="wine" if file "$1" | grep 64-bit; then winebin="wine64" fi printf '%s %q $@ || exit $?' "$winebin" "$1" > "$1.sh" chmod +x "$1.sh"
I'm not getting what you are trying to say