Search
Weird (to me) networking issue - can you help?
I have two subnets and am experiencing some pretty weird (to me) behaviour - could you help me understand what's going on?
----
Scenario 1
PC: 192.168.11.101/24 Server: 192.168.10.102/24, 192.168.11.102/24
From my PC I can connect to .11.102, but not to .10.102:
bash ping -c 10 192.168.11.102 # works fine ping -c 10 192.168.10.102 # 100% packet loss
----
Scenario 2
Now, if I disable .11.102 on the server (ip link set <dev> down) so that it only has an ip on the .10 subnet, the previously failing ping works fine.
PC: 192.168.11.101/24 Server: 192.168.10.102/24
From my PC:
bash ping -c 10 192.168.10.102 # now works fine
This is baffling to me... any idea why it might be?
----
Here's some additional information:
-
The two subnets are on different vlans (.10/24 is untagged and .11/24 is tagged 11).
-
The PC and Server are connected to the same managed switch, which however does nothing "strange" (it just leaves tags as they are on all ports).
-
The router is connected to the aformentioned switch and set to forward packets between the two subnets (I'm pretty sure how I've configured it so, plus IIUC the second scenario ping wouldn't work without forwarding).
-
The router also has the same vlan setup, and I can ping both .10.1 and .11.1 with no issue in both scenarios 1 and 2.
-
In case it may matter, machine 1 has the following routes, setup by networkmanager from dhcp:
default via 192.168.11.1 dev eth1 proto dhcp src 192.168.11.101 metric 410 192.168.11.0/24 dev eth1 proto kernel scope link src 192.168.11.101 metric 410
- In case it may matter, Machine 2 uses systemd-networkd and the routes generated from DHCP are slightly different (after dropping the .11.102 address for scenario 2, of course the relevant routes disappear):
default via 192.168.10.1 dev eth0 proto dhcp src 192.168.10.102 metric 100 192.168.10.0/24 dev eth0 proto kernel scope link src 192.168.10.102 metric 100 192.168.10.1 dev eth0 proto dhcp scope link src 192.168.10.102 metric 100 default via 192.168.11.1 dev eth1 proto dhcp src 192.168.11.102 metric 101 192.168.11.0/24 dev eth1 proto kernel scope link src 192.168.11.102 metric 101 192.168.11.1 dev eth1 proto dhcp scope link src 192.168.11.102 metric 101
----
solution
(please do comment if something here is wrong or needs clarifications - hopefully someone will find this discussion in the future and find it useful)
In scenario 1, packets from the PC to the server are routed through .11.1.
Since the server also has an .11/24 address, packets from the server to the PC (including replies) are not routed and instead just sent directly over ethernet.
Since the PC does not expect replies from a different machine that the one it contacted, they are discarded on arrival.
The solution to this (if one still thinks the whole thing is a good idea), is to route traffic originating from the server and directed to .11/24 via the router.
This could be accomplished with ip route del 192.168.11.0/24, which would however break connectivity with .11/24 adresses (similar reason as above: incoming traffic would not be routed but replies would)...
The more general solution (which, IDK, may still have drawbacks?) is to setup a secondary routing table:
bash echo 50 mytable >> /etc/iproute2/rt_tables # this defines the routing table # (see "ip rule" and "ip route show table <table>") ip rule add from 192.168.10/24 iif lo table mytable priority 1 # "iff lo" selects only # packets originating # from the machine itself ip route add default via 192.168.10.1 dev eth0 table mytable # "dev eth0" is the interface # with the .10/24 address, # and might be superfluous
Now, in my mind, that should break connectivity with .10/24 addresses just like ip route del above, but in practice it does not seem to (if I remember I'll come back and explain why after studying some more)
New Network Stack with an Unknown Issue..?
Update: It was DNS... its always DNS...
Hello there! I'm in a bit of a pickle.. I've recently bought the full budget Tp-link omada stack for my homelab. I got the following devices in my stack:
- ER605 Router
- OC200 Controller
- SG2008P PoE Switch
- EAP610 Wireless AP
- EAP625 Wireless AP (getting soon)
I've set it all up and it was working fine for the first few days of using it. However, last few days it's been working very much on and off randomly(?) . Basically devices will state they are connected to WiFi/Ethernet, but they are not actually getting it. (As seen in the picture). This is happening with our phones(Pixel7+S23U) and my server(NAS:Unraid), have not noticed any problems on our desktop PCs. So it is happening on both wired and wireless, as my server and desktop PC is connected to the switch.
I haven't done many configurations in the omada software yet, but am assuming it's something I have done that causes this... Would greatly appreciate any advice to solve/troubleshoot this!
Need help routing Wireguard container traffic through Gluetun container
The solution has been found, see the "Solution" section for the full write up and config files.
Initial Question
What I'm looking to do is to route WAN traffic from my personal wireguard server through a gluetun container. So that I can connect a client my personal wireguard server and have my traffic still go through the gluetun VPN as follows:
client <--> wireguard container <--> gluetun container <--> WAN
I've managed to set both the wireguard and gluetun container up in a docker-compose file and made sure they both work independently (I can connect a client the the wireguard container and the gluetun container is successfully connecting to my paid VPN for WAN access). However, I cannot get route traffic from the wireguard container through the gluetun container.
Since I've managed to set both up independently I don't believe that there is an issue with the docker-compose file I used for setup. What I believe to be the issue is either the routing rules in my wireguard container, or the firewall rules on the gluetun container.
I tried following this linuxserver.io guide to get the following wg0.conf template for my wireguard container:
```
[Interface]
Address = ${INTERFACE}.1
ListenPort = 51820
PrivateKey = $(cat /config/server/privatekey-server)
PostUp = iptables -A FORWARD -i %i -j ACCEPT; iptables -A FORWARD -o %i -j ACCEPT; iptables -t nat -A POSTROUTING -o eth+ -j MASQUERADE
Adds fwmark 51820 to any packet traveling through interface wg0
PostUp = wg set wg0 fwmark 51820
If a packet is not marked with fwmark 51820 (not coming through the wg connection) it will be routed to the table "51820".
PostUp = ip -4 rule add not fwmark 51820 table 51820
Creates a table ("51820") which routes all traffic through the gluetun container
PostUp = ip -4 route add 0.0.0.0/0 via 172.22.0.100
If the traffic is destined for the subnet 192.168.1.0/24 (internal) send it through the default gateway.
PostUp = ip -4 route add 192.168.1.0/24 via 172.22.0.1
PostDown = iptables -D FORWARD -i %i -j ACCEPT; iptables -D FORWARD -o %i -j ACCEPT; iptables -t nat -D POSTROUTING -o eth+ -j MASQUERADE
Along with the default firewall rules of the gluetun container
Chain INPUT (policy DROP 13 packets, 1062 bytes)
pkts bytes target prot opt in out source destination
15170 1115K ACCEPT 0 -- lo * 0.0.0.0/0 0.0.0.0/0
14403 12M ACCEPT 0 -- * * 0.0.0.0/0 0.0.0.0/0 ctstate RELATED,ESTABLISHED
1 60 ACCEPT 0 -- eth0 * 0.0.0.0/0 172.22.0.0/24
Chain FORWARD (policy DROP 4880 packets, 396K bytes) pkts bytes target prot opt in out source destination
Chain OUTPUT (policy DROP 360 packets, 25560 bytes) pkts bytes target prot opt in out source destination 15170 1115K ACCEPT 0 -- * lo 0.0.0.0/0 0.0.0.0/0 12716 1320K ACCEPT 0 -- * * 0.0.0.0/0 0.0.0.0/0 ctstate RELATED,ESTABLISHED 0 0 ACCEPT 0 -- * eth0 172.22.0.100 172.22.0.0/24 1 176 ACCEPT 17 -- * eth0 0.0.0.0/0 68.235.48.107 udp dpt:1637 1349 81068 ACCEPT 0 -- * tun0 0.0.0.0/0 0.0.0.0/0 ``` When I run the wireguard container with this configuration I can successfully connect my client however I cannot connect to any website, or ping any IP.
During my debugging process I ran tcpdump on the docker network both containers are in which showed me that my client is successfully sending packets to the wireguard container, but that no packets were sent from my wireguard container to the gluetun container. The closest I got to this was the following line:
17:27:38.871259 IP 10.13.13.1.domain > 10.13.13.2.41280: 42269 ServFail- 0/0/0 (28)
Which I believe is telling me that the wireguard server is trying, and failing, to send packets back to the client.
I also checked the firewall rules of the gluetun container and got the following results: ``` Chain INPUT (policy DROP 13 packets, 1062 bytes) pkts bytes target prot opt in out source destination 18732 1376K ACCEPT 0 -- lo * 0.0.0.0/0 0.0.0.0/0 16056 12M ACCEPT 0 -- * * 0.0.0.0/0 0.0.0.0/0 ctstate RELATED,ESTABLISHED 1 60 ACCEPT 0 -- eth0 * 0.0.0.0/0 172.22.0.0/24
Chain FORWARD (policy DROP 5386 packets, 458K bytes) pkts bytes target prot opt in out source destination
Chain OUTPUT (policy DROP 360 packets, 25560 bytes) pkts bytes target prot opt in out source destination 18732 1376K ACCEPT 0 -- * lo 0.0.0.0/0 0.0.0.0/0 14929 1527K ACCEPT 0 -- * * 0.0.0.0/0 0.0.0.0/0 ctstate RELATED,ESTABLISHED 0 0 ACCEPT 0 -- * eth0 172.22.0.100 172.22.0.0/24 1 176 ACCEPT 17 -- * eth0 0.0.0.0/0 68.235.48.107 udp dpt:1637 1660 99728 ACCEPT 0 -- * tun0 0.0.0.0/0 0.0.0.0/0 ``` Which shows that the firewall for the gluetun container is dropping all FORWARD traffic which (as I understand it) is the sort of traffic I'm trying to set up. What is odd is that I don't see any of those packets in the tcpdump of the docker network.
Has anyone successfully set this up or have any indication on what I should try next? At this point any ideas would be helpful, whether that be more debugging steps or recommendations for routing/firewall rules.
While there have been similar posts on this topic (Here and Here) the responses on both did not really help me.
---
Solution
Docker Compose Setup
My final working setup uses the following docker-compose file:
networks: default: ipam: config: - subnet: 172.22.0.0/24 services: gluetun_vpn: image: qmcgaw/gluetun:latest container_name: gluetun_vpn cap_add: - NET_ADMIN # Required environment: - VPN_TYPE=wireguard # I tested this with a wireguard setup # Setup Gluetun depending on your provider. volumes: - {docker config path}/gluetun_vpn/conf:/gluetun - {docker config path}/gluetun_vpn/firewall:/iptables sysctls: # Disables ipv6 - net.ipv6.conf.all.disable_ipv6=1 restart: unless-stopped networks: default: ipv4_address: 172.22.0.100 wireguard_server: image: lscr.io/linuxserver/wireguard:latest container_name: wg_server cap_add: - NET_ADMIN environment: - TZ=America/Detroit - PEERS=1 - SERVERPORT=3697 # Optional - PEERDNS=172.22.0.100 # Set this as the Docker network IP of the gluetun container to use your vpn's dns resolver ports: - 3697:51820/udp # Optional volumes: - {docker config path}/wg_server/conf:/config sysctls: - net.ipv4.conf.all.src_valid_mark=1 networks: default: ipv4_address: 172.22.0.2 restart: unless-stopped
Once you get both docker containers working you still need to edit some configuration files.
Wireguard Server Setup
After the wireguard container setup you need to edit {docker config path}/wg_server/conf/templates/server.conf to the following:
``` [Interface] Address = ${INTERFACE}.1 ListenPort = 51820 PrivateKey = $(cat /config/server/privatekey-server)
Default from the wg container
PostUp = iptables -A FORWARD -i %i -j ACCEPT; iptables -A FORWARD -o %i -j ACCEPT; iptables -t nat -A POSTROUTING -o eth+ -j MASQUERADE
Add this section
Adds fwmark 51820 to any packet traveling through interface wg0
PostUp = wg set wg0 fwmark 51820
If a packet is not marked with fwmark 51820 (not coming through the wg connection) it will be routed to the table "51820".
PostUp = ip -4 rule add not fwmark 51820 table 51820 PostUp = ip -4 rule add table main suppress_prefixlength 0
Creates a table ("51820") which routes all traffic through the vpn container
PostUp = ip -4 route add 0.0.0.0/0 via 172.22.0.100 table 51820
If the traffic is destined for the subnet 192.168.1.0/24 (internal) send it through the default gateway.
PostUp = ip -4 route add 192.168.1.0/24 via 172.22.0.1
Default from the wg container
PostDown = iptables -D FORWARD -i %i -j ACCEPT; iptables -D FORWARD -o %i -j ACCEPT; iptables -t nat -D POSTROUTING -o eth+ -j MASQUERADE ```
The above config is a slightly modified setup from this linuxserver.io tutorial
Gluetun Setup
If you've setup your gluetun container properly the only thing you have to do is create {docker config path}/gluetun_vpn/firewall/post-rules.txt containing the following:
iptables -t nat -A POSTROUTING -o tun+ -j MASQUERADE iptables -t filter -A FORWARD -d 172.22.0.2 -j ACCEPT iptables -t filter -A FORWARD -s 172.22.0.2 -j ACCEPT
These commands should be automatically run once you restart the gluetun container. You can test the setup by running iptables-legacy -vL -t filter from within the gluetun container. Your output should look like:
```
Chain INPUT (policy DROP 7 packets, 444 bytes)
pkts bytes target prot opt in out source destination
27512 2021K ACCEPT all -- lo any anywhere anywhere
43257 24M ACCEPT all -- any any anywhere anywhere ctstate RELATED,ESTABLISHED
291 28191 ACCEPT all -- eth0 any anywhere 172.22.0.0/24
These are the important rules
Chain FORWARD (policy DROP 12276 packets, 2476K bytes) pkts bytes target prot opt in out source destination 17202 8839K ACCEPT all -- any any anywhere 172.22.0.2 26704 5270K ACCEPT all -- any any 172.22.0.2 anywhere
Chain OUTPUT (policy DROP 42 packets, 2982 bytes) pkts bytes target prot opt in out source destination 27512 2021K ACCEPT all -- any lo anywhere anywhere 53625 9796K ACCEPT all -- any any anywhere anywhere ctstate RELATED,ESTABLISHED 0 0 ACCEPT all -- any eth0 c6d5846467f3 172.22.0.0/24 1 176 ACCEPT udp -- any eth0 anywhere 64.42.179.50 udp dpt:1637 2463 148K ACCEPT all -- any tun0 anywhere anywhere ```
And iptables-legacy -vL -t nat which should look like:
```
Chain PREROUTING (policy ACCEPT 18779 packets, 2957K bytes)
pkts bytes target prot opt in out source destination
Chain INPUT (policy ACCEPT 291 packets, 28191 bytes) pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 7212 packets, 460K bytes) pkts bytes target prot opt in out source destination
This is the important rule
Chain POSTROUTING (policy ACCEPT 4718 packets, 310K bytes) pkts bytes target prot opt in out source destination 13677 916K MASQUERADE all -- any tun+ anywhere anywhere ```
The commands in post-rules.txt are a more precises version of @[email protected] solution in the comments.
Selectively chaining a VPN to another while allowing split tunnelling on clients?
Currently, I have two VPN clients on most of my devices:
- One for connecting to a LAN
- One commercial VPN for privacy reasons
I usually stay connected to the commercial VPN on all my devices, unless I need to access something on that LAN.
This setup has a few drawbacks:
- Most commercial VPN providers have a limit on the number of simulations connected clients
- I either obfuscate my IP or am able to access resources on that LAN, including my Pi-Hole fur custom DNS-based blocking
One possible solution for this would be to route all internet traffic through a VPN client on the router in the LAN and figuring out how to still be able to at least have a port open for the VPN docker container allowing access to the LAN. But then the ability to split tunnel around that would be pretty hard to achieve.
I want to be able to connect to a VPN host container on the LAN, which in turn routes all internet traffic through another VPN client container while allowing LAN traffic, but still be able to split tunnel specific applications on my Android/Linux/iOS devices.
Basically this:
+---------------------+ internet traffic +--------------------+ | | remote LAN traffic | | | Client |------------------->|VPN Host Container | | (Android/iOS/Linux) | |in remote LAN | | | | | +---------------------+ +--------------------+ | | | | remote LAN traffic| | internet traffic split tunneled traffic| |-------- | | | v v | +---------------------------+ +---------------------+ v | | | regular LAN or | +-----------+ | VPN Client Container | | internet connection | |remote LAN | | connects to commercial VPN| +---------------------+ +-----------+ | | | | +---------------------------+
Any recommendations on how to achieve this, especially considering client apps for Android and iOS with the ability to split tunnel per application?
Update:
Got it by following this guide.
Ended up modifying this setup to have better control over potential IP leakage
Immich keeps restarting the backup
Hi guys! I'm having my first attempt at Immich (...and docker, since I'm at it). So I have successfully set it up (I think), and connected the phone and it started uploading. I have enabled foreground and background backup, and I have only chosen the camera album from my Pixel/GrapheneOS phone. Thing is, after a while (when the screen turns off for a while, even though the app is unrestricted in Android/GrapheneOS, or whenever changing apps...or whenever it feels like), the backup seems to start again from scratch, uploading again and again the first videos from the album (the latest ones, from a couple of days ago), and going its way until somewhere in December 2023...which is where at some point decides to go back and re-do May 2024. It's been doing this a bunch of times. I've seen mentioned a bunch of times that I should set client_max_body_size on nginx to something large like 5000MB. However in my case it's set to 0, which should read as unrestricted. It doesn't skip large videos of several hundreds megs, it does seem to go through the upload process...but then it keeps redoing them after a while.
Any idea what might be failing? Why does it keep restarting the backup? By the way, I took a screenshot of the backup a couple days ago, and both the backed up asset number and the remainder has kept the same since (total 2658, backup 179, remainder 2479). This is a couple of days now going through what I'd think is the same files over and over?
SOLVED: So it was about adding the client_max_body_size value to my nginx server. I thought I did, so I was ignoring this even though I saw it mentioned multiple times. Mine is set to value 0, not 50000M as suggested on other threads, but I thought it should work. But then again, it was in the wrong section, applying to a different service/container, not Immich. Adding it to Immich too (with 0, in my case, which should set it to "unlimited") worked immediately after restarting nginx service. Thanks everyone for all the follow ups and suggestions!
I have issues with asymmetric routing
{kind=link}
{kind=link}
One is the route from my Proxmox (vimes) server to my NAS, (colon) going via my Router (pessimal) (as it should be) Second one is my NAS going to Proxmox directly. However I didn't set any static routes and this is causing issues as the Router Firewalls those Asymmetric Connections. This is happening since I upgraded Proxmox... I am not the best at network stuff, so if someone has some pointers I'd be most grateful.
I'm a moron and had a wrong subnet mask.
Traefik + Vaultwarden 502 Error
Edit: Thanks for the help, issue was solved! Had Traefik's loadbalancer set to route to port 8081, not the internal port of 80. Whoops.
Intro
HI everyone. I've been busy configuring my homelab and have run into issues with Traefik and Vaultwarden running within Podman. I've already successfully set up Home Assistant and Homepage but for the life of me cannot get things working. I'm hoping a fresh pair of eyes would be able to spot something I missed or provide some advice. I've tried to provide all the information and logs relevant to the situation.
Expected Behavior:
- Requests for
*.fenndev.networkare sent to my Traefik server. - Incoming HTTPS requests to
vault.fenndev.networkare forwarded to Vaultwarden- HTTP requests are upgraded to HTTPS
- Vaultwarden is accessible via
https://vault.fenndev.networkand utilizes the wildcard certificates generated by Traefik.
Quick Facts
Overview
- I'm running Traefik and Vaultwarden in Podman, using Quadlet
- Traefik and Vaultwarden, along with all of my other services, are part of the same
fenndev_defaultnetwork - Traefik is working correctly with Home assistant, Adguard Home, and Homepage, but returns a
502 Bad Gatewayerror with Vaultwarden - I've verified that port
8081is open on my firewall and my service is reachable at{SERVER_IP}:8081. 10.89.0.132is the internal Podman IP address of the Vaultwarden container
Versions
Server: AlmaLinux 9.4
Podman: 4.9.4-rhel
Traefik: v3
Vaultwarden: alpine-latest (1.30.5-alpine I believe)
Error Logs
Traefik Log:
2024-05-11T22:09:53Z DBG github.com/traefik/traefik/v3/pkg/server/service/proxy.go:100 > 502 Bad Gateway error="dial tcp 10.89.0.132:8081: connect: connection refused"
cURL to URL: ``` [fenndev@bastion ~]$ curl -v https://vault.fenndev.network
- Trying 192.168.1.169:443...
- Connected to vault.fenndev.network (192.168.1.169) port 443 (#0)
- ALPN, offering h2
- ALPN, offering http/1.1
- CAfile: /etc/pki/tls/certs/ca-bundle.crt
- TLSv1.0 (OUT), TLS header, Certificate Status (22): ```
Config Files
vaultwarden.container file: ``` [Unit] Description=Password After=network-online.target [Service] Restart=always RestartSec=3
[Install]
Start by default on boot
WantedBy=multi-user.target default.target
[Container] Image=ghcr.io/dani-garcia/vaultwarden:latest-alpine Exec=/start.sh EnvironmentFile=%h/.config/vault/vault.env ContainerName=vault Network=fenndev_default
Security Options
SecurityLabelType=container_runtime_t NoNewPrivileges=true
Volumes
Volume=%h/.config/vault/data:/data:Z
Ports
PublishPort=8081:80
Labels
Label=traefik.enable=true
Label=traefik.http.routers.vault.entrypoints=web
Label=traefik.http.routers.vault-websecure.entrypoints=websecure
Label=traefik.http.routers.vault.rule=Host(vault.fenndev.network)
Label=traefik.http.routers.vault-websecure.rule=Host(vault.fenndev.network)
Label=traefik.http.routers.vault-websecure.tls=true
Label=traefik.http.routers.vault.service=vault
Label=traefik.http.routers.vault-websecure.service=vault
Label=traefik.http.services.vault.loadbalancer.server.port=8081
Label=homepage.group="Services" Label=homepage.name="Vaultwarden" Label=homepage.icon=vaultwarden.svg Label=homepage.description="Password Manager" Label=homepage.href=https://vault.fenndev.network ```
vault.env file:
LOG_LEVEL=debug DOMAIN=https://vault.fenndev.network
Using Nextcloud as a directory/folder/remote location
Hi guys
Is there any way to access Nextcloud files (self hosted) in a file manager just like a regular directory or remote location? So the way iCloud or Dropbox allow you to access files and use them for example to upload them in a browser. So far I only managed to access the files in the Nextcloud WebUI or via the command line (but then a resync is necessary).
Any input is appreciated. Thanks!
Any alternative to vnstat for Windows?
cross-posted from: https://lemmy.ml/post/15121280
> preferably with a web console (not required)
Edit: I went with this as a solution for now: https://github.com/Ashfaaq18/OpenNetMeter
ETIMEDOUT Error when trying to access Immich GUI
Edit: I found the solution. I was missing a few environment variables.
These are the functioning Ansible tasks to deploy Immich:
Solution
```
-
name: create Immich network community.docker.docker_network: name: immich-network state: present
-
name: deploy Immich-Redis community.docker.docker_container: name: immich-redis image: registry.hub.docker.com/library/redis:6.2-alpine@sha256:84882e87b54734154586e5f8abd4dce69fe7311315e2fc6d67c29614c8de2672 restart_policy: always networks: - name: immich-network
-
name: deploy Immich-Postgres community.docker.docker_container: name: immich-postgres image: registry.hub.docker.com/tensorchord/pgvecto-rs:pg14-v0.2.0@sha256:90724186f0a3517cf6914295b5ab410db9ce23190a2d9d0b9dd6463e3fa298f0 restart_policy: always volumes: - "{{ nvme_mount_point }}/immich/postgres:/var/lib/postgresql/data" env: POSTGRES_DB: "{{ immich_postgres_db_name }}" POSTGRES_USER: "{{ immich_postgres_db_user }}" POSTGRES_PASSWORD: "{{ immich_postgres_db_password }}" networks: - name: immich-network
-
name: deploy Immich-Machine-Learning community.docker.docker_container: name: immich-machine-learning image: ghcr.io/immich-app/immich-machine-learning:release restart_policy: always volumes: - "{{ nvme_mount_point }}/immich/model-cache:/cache" networks: - name: immich-network env: DB_DATABASE_NAME: "{{ immich_postgres_db_name }}" DB_USERNAME: "{{ immich_postgres_db_user }}" DB_PASSWORD: "{{ immich_postgres_db_password }}" DB_DATA_LOCATION: "{{ nvme_mount_point }}/immich/postgres" DB_HOSTNAME: immich-postgres REDIS_HOSTNAME: immich-redis
-
name: deploy Immich-Microservices community.docker.docker_container: name: immich-microservices image: ghcr.io/immich-app/immich-server:release restart_policy: always command: ['start.sh', 'microservices'] volumes: - "{{ hdd_mount_point}}/immich/library:/usr/src/app/upload" - /etc/localtime:/etc/localtime:ro networks: - name: immich-network env: DB_DATABASE_NAME: "{{ immich_postgres_db_name }}" DB_USERNAME: "{{ immich_postgres_db_user }}" DB_PASSWORD: "{{ immich_postgres_db_password }}" DB_DATA_LOCATION: "{{ nvme_mount_point }}/immich/postgres" DB_HOSTNAME: immich-postgres REDIS_HOSTNAME: immich-redis
-
name: deploy Immich-Server community.docker.docker_container: name: immich-server image: ghcr.io/immich-app/immich-server:release restart_policy: always command: ['start.sh', 'immich'] volumes: - "{{ hdd_mount_point}}/immich/library:/usr/src/app/upload" - /etc/localtime:/etc/localtime:ro ports: - "2283:3001" networks: - name: immich-network env: DB_DATABASE_NAME: "{{ immich_postgres_db_name }}" DB_USERNAME: "{{ immich_postgres_db_user }}" DB_PASSWORD: "{{ immich_postgres_db_password }}" DB_DATA_LOCATION: "{{ nvme_mount_point }}/immich/postgres" DB_HOSTNAME: immich-postgres REDIS_HOSTNAME: immich-redis ```
I'm trying to install Immich via Ansible and so far so good. The containers are all running and as long as I don't try to access it the logs all look fine but as soon as I try to access the GUI I get the following error spammed in the immich-server container log and the browser just shows a timeout and doesn't connect to the GUI.
[Nest] 7 - 05/02/2024, 9:20:45 AM ERROR [TypeOrmModule] Unable to connect to the database. Retrying (5)... Error: Connection terminated due to connection timeout at Connection.<anonymous> (/usr/src/app/node_modules/pg/lib/client.js:132:73) at Object.onceWrapper (node:events:632:28) at Connection.emit (node:events:518:28) at Socket.<anonymous> (/usr/src/app/node_modules/pg/lib/connection.js:63:12) at Socket.emit (node:events:518:28) at TCP.<anonymous> (node:net:337:12)
Error: connect ETIMEDOUT at Socket.<anonymous> (/usr/src/app/node_modules/ioredis/built/Redis.js:170:41) at Object.onceWrapper (node:events:632:28) at Socket.emit (node:events:518:28) at Socket._onTimeout (node:net:589:8) at listOnTimeout (node:internal/timers:573:17) at process.processTimers (node:internal/timers:514:7) { errorno: 'ETIMEDOUT', code: 'ETIMEDOUT', syscall: 'connect' }
Here are my Ansible tasks to deploy Immich:
Ansible tasks with missing ENV variables
``` yml
-
name: create Immich network community.docker.docker_network: name: immich-network state: present
-
name: deploy Immich-Redis community.docker.docker_container: name: immich-redis image: registry.hub.docker.com/library/redis:6.2-alpine@sha256:84882e87b54734154586e5f8abd4dce69fe7311315e2fc6d67c29614c8de2672 restart_policy: always networks: - name: immich-network
-
name: deploy Immich-Postgres community.docker.docker_container: name: immich-postgres image: registry.hub.docker.com/tensorchord/pgvecto-rs:pg14-v0.2.0@sha256:90724186f0a3517cf6914295b5ab410db9ce23190a2d9d0b9dd6463e3fa298f0 restart_policy: always volumes: - "{{ nvme_mount_point }}/immich/postgres:/var/lib/postgresql/data" env: POSTGRES_DB: "{{ immich_postgres_db_name }}" POSTGRES_USER: "{{ immich_postgres_db_user }}" POSTGRES_PASSWORD: "{{ immich_postgres_db_password }}" networks: - name: immich-network
-
name: deploy Immich-Machine-Learning community.docker.docker_container: name: immich-machine-learning image: ghcr.io/immich-app/immich-machine-learning:release restart_policy: always volumes: - "{{ nvme_mount_point }}/immich/model-cache:/cache" networks: - name: immich-network env: DB_DATABASE_NAME: "{{ immich_postgres_db_name }}" DB_USERNAME: "{{ immich_postgres_db_user }}" DB_PASSWORD: "{{ immich_postgres_db_password }}"
-
name: deploy Immich-Microservices community.docker.docker_container: name: immich-microservices image: ghcr.io/immich-app/immich-server:release restart_policy: always command: ['start.sh', 'microservices'] volumes: - "{{ hdd_mount_point}}/immich/library:/usr/src/app/upload" - /etc/localtime:/etc/localtime networks: - name: immich-network env: DB_DATABASE_NAME: "{{ immich_postgres_db_name }}" DB_USERNAME: "{{ immich_postgres_db_user }}" DB_PASSWORD: "{{ immich_postgres_db_password }}"
-
name: deploy Immich-Server community.docker.docker_container: name: immich-server image: ghcr.io/immich-app/immich-server:release restart_policy: always command: ['start.sh', 'immich'] volumes: - "{{ hdd_mount_point}}/immich/library:/usr/src/app/upload" - /etc/localtime:/etc/localtime ports: - "2283:3001" networks: - name: immich-network env: DB_DATABASE_NAME: "{{ immich_postgres_db_name }}" DB_USERNAME: "{{ immich_postgres_db_user }}" DB_PASSWORD: "{{ immich_postgres_db_password }}" ```
The variables are:
immich_postgres_db_name: immich immich_postgres_db_user: postgres immich_postgres_db_password: postgres
for testing purposes.
I'm currently running this on a Hyper-V VM running Fedora 39 Server Edition.
I don't know how to fix this issue, can someone help me?
I found this issue on the Immich GitHub where I found a possible fix regarding the firewall that it might block something but it didn't really help.
So I'm thankful for any ideas you can throw my way. Tell me if you need any more info.
Edit: Overlooked an error in the log and added it to the post.
Can’t login to Syncthing GUI with Ngnix Proxy Manager
Edit: Solution is in Nginx I disabled these: Cache Assets, Block Common Exploits, Websockets Support.
I can login using the local IP 192.168.1.2:9101, but when I route that with Nginx, It won't.
I have the GUI listen address as : 0.0.0.0:9101
I've been googling for hours but I can't find anything, In browser console it says
Failed to load resource: the server responded with a status of 403 ()
syncthing.my.domain.com/:1 Refused to execute script from 'https://syncthing.my.domain.com/meta.js' because its MIME type ('text/plain') is not executable, and strict MIME type checking is enabled.
Audiobookshelf not fetching latest podcast episodes
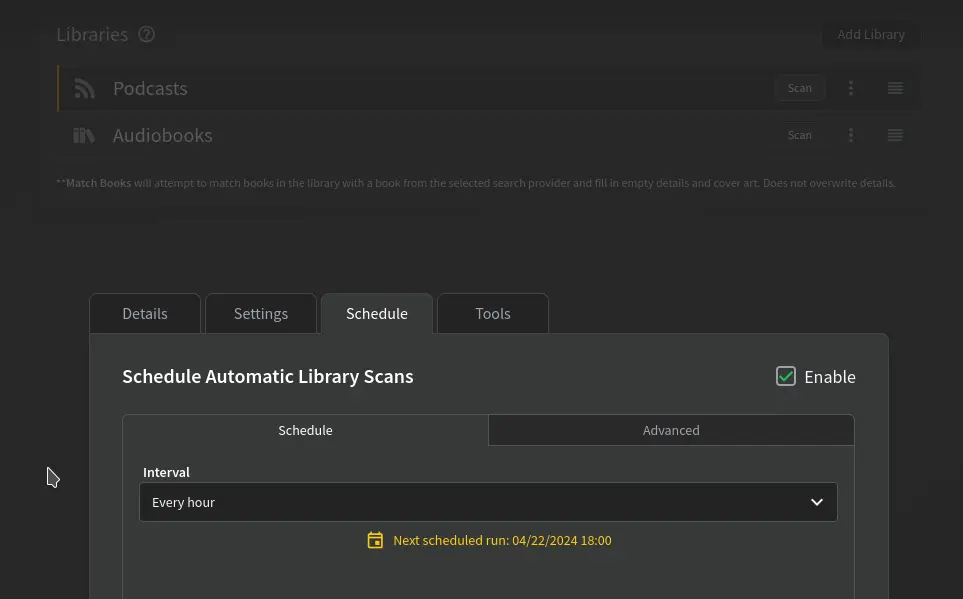
Hiya, quickly wondering if anyone has had any issues with ABS not fetching/pulling latest podcast episodes? I added my podcasts via OPML, around a week ago, and it doesn't seem to be pulling in any new episodes. I've set a schedule to scan the lib each hour, but im assuming this feature is just for scanning for new local files and not fetching. Anyone got any tips on what to do here? !
{kind=link}
Sudden Issues
Suddenly, things aren't loading properly. For example Heimdall takes forever to load and Navidrome is timing out.
When I do docker-compose pull
It says says
Error response from daemon: Get "https://registry-1.docker.io/v2/" net/http: request cancelled while waiting for connection (Client.Timeout exceeded while awaiting headers)
Anyone know what's up or how to fix it?
Edit: checking the /etc/resolv.conf
It says
search cable.virginm.net nameserver 194.168.4.100 nameserver 194.168.8.100
Though neither are opening anything from a browser
Not sure if it's helpful, but this is what the networking bridge says via Portainer
``` Network details
Name: bridge Id: Oc3f5ce6ffc566ee80/1689056f11d491269849967877933858053581742-978 Driver: bridge Scope: local Attachable: false Internal: false IPV4 Subnet - 172.120.0/16: IPV4 Gateway - 172.17.0.1 IPV4 P Range: PV4 Excluded IPs
Access control
Ownership: public
Network options
com.docker network.bridge default_bridge: true com.docker.network.bridge.enable.icc: true com docket.network.bridge.enable_ip.masquerade: true com docker.network.bridge.host_binding_ipv4: 0.0.0.0 com.docker.network.bridge.name: docker0 com.docker.network.driver.mtu: 1500 ```
I suspect it may be this bug https://github.com/moby/moby/issues/47662
##Resolution Turns out it was just Virgin Media's router doing shit. A factory reset of the router fixed my issues.
Proxmox not conncected to internet, but is reachable on LAN
[SOLVED] Turns out I'm just a bigger moron than I thought. The MAC address of my server had accidentally been flagged in my router for black listing.
As the title says, my proxmox host is apparently not able to reach the internet anymore, not sure for how long this has been an issue, I rarely work on the host itself. It can ping other devices on my network just fine, and other devices can ping it. I can also SSH in to it and access the web interface. My VMs are connected to the internet without any issues. I don't need to access the host remotely/outside my home network, this is just for updating it etc.
I can't see the host under active devices in my router though.
I have been trying to figure why, but so far without any luck.
-sorta Problems running adguardhome
Edit: So a solution I just found is that if I remove the second DNS from my router (1.1.1.1) then all traffic goes through adguard. This works but if I go on vacation and my parents are still home and this device dies or something then my mom will have no idea what to do...
Hello,
I have adguardhome running on a raspberry pi via docker compose. I once had tailscale installed on it but it has sense been uninstalled.
Using for example my phone when at home if it is on my tailnet the adguard works as intended and blocks ads trackers etc. But If at home and disconnected from my tailnet it does not go through adguard at all. So all my family members do not have the benefit of this and anything not on my tailnet. I would rather have it work for everyone and not sure how to fix or where I went wrong in the setup.
For the setup guide for adguard it says > AdGuard Home DNS server is listening on the following addresses: 127.0.0.1 172.18.0.2
So I added 172.18.0.2 to my /etc/systemd/resolved.conf file because before it had only DNS=127.0.0.1. This seems to have not worked unless I need to restart for it to take effect
looks like this now
```
Entries in this file show the compile time defaults. Local configuration
should be created by either modifying this file, or by creating "drop-ins" in
the resolved.conf.d/ subdirectory. The latter is generally recommended.
Defaults can be restored by simply deleting this file and all drop-ins.
Use 'systemd-analyze cat-config systemd/resolved.conf' to display the full config.
See resolved.conf(5) for details.
[Resolve]
Some examples of DNS servers which may be used for DNS= and FallbackDNS=:
Cloudflare: 1.1.1.1#cloudflare-dns.com 1.0.0.1#cloudflare-dns.com 2606:4700:4700::1111#cloudflare-dns.com 2606:4700:4700::1001#cloudflare-dns.com
Google: 8.8.8.8#dns.google 8.8.4.4#dns.google 2001:4860:4860::8888#dns.google 2001:4860:4860::8844#dns.google
Quad9: 9.9.9.9#dns.quad9.net 149.112.112.112#dns.quad9.net 2620:fe::fe#dns.quad9.net 2620:fe::9#dns.quad9.net
DNS=127.0.0.1 172.18.0.2 #FallbackDNS= #Domains= #DNSSEC=no #DNSOverTLS=no #MulticastDNS=no #LLMNR=no #Cache=no-negative #CacheFromLocalhost=no DNSStubListener=no #DNSStubListenerExtra= #ReadEtcHosts=yes #ResolveUnicastSingleLabel=no ```
docker-compose file ``` version: '3.3' services: run: container_name: adguardhome restart: unless-stopped volumes: - '/home/Blxter/server/compose/adguard-home/config/adguardhome/workdir:/opt/adguardhome/work' - '/home/Blxter/server/compose/adguard-home/config/adguardhome/confdir:/opt/adguardhome/conf' ports: - '53:53/tcp' - '53:53/udp' - '67:67/udp' - '68:68/udp' - '68:68/tcp' - '80:80/tcp' - '443:443/tcp' - '443:443/udp' - '3005:3000/tcp' image: adguard/adguardhome ```` Not sure what other info is needed to help moderately new to this Thanks
(Tailscale) Re-authenticate Samba share to gain access each boot?
Hiya, Edit: Solved by tweaking the ACL in Tailscale, more info on that here; https://tailscale.com/kb/1193/tailscale-ssh
I am accessing my Samba folder from my remote server, over Tailscale. However, this means, each time I close the lid of my laptop or reboot. I need to re-authenticate this, I don't know why. Is there a way around this? Or a better solution?
I've added the share(folder) to "places" via Dolphin, but in order to actually be able to access the share i need to go into the terminal and enter "sftp myserver:port". After that the share will work as normal, until next boot.
I prefer accessing my files via Tailscale, it's very convenient and secure in most cases. I am storing my notes for Obsidian and other frequently used files via this share. The server is running Unraid, my laptop is running an Immutable distro called Aurora (part of Bluefin Project).
Any help appricated!
Temporarily hosting on Oracle Free tier.
Solution : Don't be stupid. Open the proper ports.
-------------------------------------------------------------
Hey there!
So, I'm getting ready to move from places to places for the next six months and it's going to be a bit of a hassle. My servers will be offline until I find a permanent home, which is stressing me out because I rely on a bunch of services I host for my daily routine.
So I've set up an Oracle free tier account so I can still access my favorite services while I'm in limbo. I'm using docker and Portainer to manage everything, and so far Serge (for the lolz) and Vikunja are up and running with no issues using the IP Oracle provided.
But when I tried to set up Bookstack, Whoogle and Searxng, they installed fine but for some reason they won't open. I've checked the logs and there are no errors, I just keep getting a timeout message in my browser.
I haven't tested any other services yet, but I'm stumped as to why these two won't cooperate. I'm just a casual hobbyist and not an expert, so if anyone could lend a hand, I'd really appreciate it. Thanks!
Podman won't start Pihole with an error saying that it can't bind to port 53, as it is already in use, but nothing is using port 53.
Solution
It was found (here, and here) that Podman uses its own DNS server, aardvark-dns which is bound to port 53 (this explains why I was able to bind to 53 with nc on the host while the container would still fail). So the solution is to bridge the network for that port. So, in the compose file, the ports section would become:
```yaml
ports:
- "<host-ip>:53:53/tcp"
- "<host-ip>:53:53/udp"
- "80:80/tcp"
```
where
<host-ip>is the ip of the machine running the container — e.g.192.168.1.141.
---
Original Post
I so desperately want to bash my head into a hard surface. I cannot figure out what is causing this issue. The full error is as follows:
txt Error: cannot listen on the UDP port: listen udp4 :53: bind: address already in use
This is my compose file:
yaml version: "3" services: pihole: container_name: pihole image: docker.io/pihole/pihole:latest ports: - "53:53/tcp" - "53:53/udp" - "80:80/tcp" environment: TZ: '<redacted>' volumes: - './etc-pihole:/etc/pihole' - './etc-dnsmasq.d:/etc/dnsmasq.d' restart: unless-stopped
and the result of # ss -tulpn:
txt Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port Process udp UNCONN 0 0 [fe80::e877:8420:5869:dbd9]:546 *:* users:(("NetworkManager",pid=377,fd=28)) tcp LISTEN 0 128 0.0.0.0:22 0.0.0.0:* users:(("sshd",pid=429,fd=3)) tcp LISTEN 0 128 [::]:22 [::]:* users:(("sshd",pid=429,fd=4))
I have looked for possible culprit services like systemd-resolved. I have tried disabling Avahi. I have looked for other potential DNS services. I have rebooted the device. I am running the container as sudo (so it has access to all ports). I am quite at a loss.
- Raspberry Pi Model 1 B Rev 2
- Raspbian (bookworm)
- Kernel v6.6.20+rpt-rpi-v6
- Podman v4.3.1
- Podman Compose v1.0.3
EDIT (2024-03-14T22:13Z)
For the sake of clarity, # netstat -pna | grep 53 shows nothing on 53, and # lsof -i -P -n | grep LISTEN shows nothing listening to port 53 — the only listening service is SSH on 22, as expected.
Also, as suggested here, I tried manually binding to port 53, and I was able to without issue.
Self Hosted Calendar
Hi, everyone!
For several years, I've relied on NextCloud as a substitute for Google services. The time has come to say goodbye and move on in life. I've decided to replace my NextCloud instance with separate services for files, calendar, photos, notes, and to-do lists.
I've already found alternatives for all services, except for the calendar.
Does anyone have experience with FOSS projects that would allow me to self-host a calendar? I'm looking for something that supports CalDAV, has its own (pretty) user interface (webui), caters to multiple users, and supports multiple calendars.
And if anyone is interested in the alternatives I've found for each NextCloud component, here's the list:
NextCloud Files -> File Browser NextCloud Notes -> Joplin NextCloud Photos -> Immich NextCloud Tasks -> Vikunja NextCloud Calendar -> ???___
Edit:
In the end, I used Radicale software. I deployed it in a docker container and it worked almost right out of the box.
Getting into the UEFI menu
My dearest,
I just got myself a lil' HP Elitedesk 800 G2 mini and am all set to run my home server on there. But I have troubles entering the UEFI menu. I don't know what they did with Windows 10, but I can't get there the usual way (i.e., hitting random f-buttons or esc during startup). I checked out the online Windows support and found this link with options to access the UEFI menu from within Windows:
https://www.isunshare.com/windows-password/four-methods-to-access-uefi-bios-setup.html
However, even when the computer is supposed to reboot into UEFI, it always sends me back to the normal login screen. By now, I ran out of ideas what to try.
Did anyone experience similar problems?
Edit: Got it working with different keyboard/display combination. The reboot from within Windows thing still didn't work, but starting from powered off and hitting f10 a few times did it this time. I think the main problem was with my displayport to HDMI converter at home, which apparently caused some delays - and maybe the fact that it's connected to a TV at home, not a regular display. Also, if you don't stop hitting f10 at some point, apparently you get sent back to normal booting. I didn't investigate that problem further though.