Map of 2000+ lemmy communities
Map of 2000+ lemmy communities
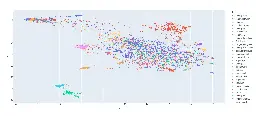
This is my first try at creating a map of lemmy. I based it on the overlap of commentors that visited certain communities.
I only used communities that were on the top 35 active instances for the past month and limited the comments to go back to a maximum of August 1 2024 (sometimes shorter if I got an invalid response.)
I scaled it so it was based on percentage of comments made by a commentor in that community.
Here is the code for the crawler and data that was used to make the map:
What do the X and Y Axis represent?
Well I used dimensionality reduction to make it 2D so the axes are how the algorithm chose to compress it.
The original data had each data point as a community and the features as a frequency of a user posting in that community.
What is [email protected] doing over with the red dots 🤔
Either the people in [email protected] are pretty horny or its an artifact of the dimensionality reduction and means nothing.
Edit: Actually it could also be that it just didn't collect enough data on that community and the most recent person was also active in nsfw communities. I was only able to get back 14ish days in the data for lemmy.world. They produce way to many comments and I got kicked out early.
This community has only two posts and a few comments. The algorithm has very few information on such tiny communities.
It would probably be useful to only include communities with a minimum amount of interaction to avoid such outliers.
The libertarians are right next to the bigtiddygothgf lol
Steamdeck is right next to animefeet
That's, great, thanks !
Reposting to [email protected]
Would you be able to take a screenshot of the map and edit that in as the link URL? Nice thumbnails help a post be seen, and it might let people see the map when the site is getting a hug of death 😄Then just have the website link at the top of the postedit: It loaded for me, and I see why a screenshot wouldn't make sense. There's so much cool detail, thanks for sharing!
I was somehow able to get both a picture and url added and it looks much better. Thx.
This is really awesome! I saw your post the other day about it and thought it was a great idea. You work quick! I already found a new community I would not have thought to look for otherwise.
It is hard for me to see and manipulate on mobile, but that's totally on me. So I'll be back in a bit. I'm sure someone smarter than me may have more helpful input than that if you are looking for feedback!
So I thought I was gonna head to bed, but... guess I can stay up and peruse for a little while...
Thank you!!
[email protected] is there right next to [email protected] at [9.6, 38.3]. I guess someone is excited about their wives being pregnant. :)
Pretty cool graph. It was funny to see the two lemmy.World porn communities in a see of lemmynsfw. I was completely unaware lemmy.World hosted porn.
Very cool!
Do you be have any idea how tolling scraping these data is for the servers?
If this is something you want to keep working on, maybe it could be combined with a sort of Threadiverse fund raiser: we collectively gather funds to cover the cost of scraping (plus some for supporting the threadiverse, ideally), and once we reach the target you release the map based on the newest data and money is distributed proportionally to the different instances.
Maybe it's a stupid idea, or maybe it would add too much pressure into the equation. But I think it could be fun! :)
I had to try scraping the websites multiple times because of stupid bugs I put in the code beforehand, so I might of put more strain on the instances than I meant too. If I did this again it would hopefully be much less tolling on the servers.
As for the cost of scraping it actually isn't that hard I just had it running in the background most of the time.
So more dots means more activity total for that communities users on any community in the top 35?
Wouldn't a bar graph be sufficient?
For example most of the red dots to the top right are nsfw communities and it was able to clump like that because the people that comment in those communities tend to comment in the other nsfw communities as well.
edit: left -> right
Ah cool, self segregating proximity map. The format makes more sense with this explanation, thank you.
I didn't measure activity for this map. Each dot represents a community. I only used the communities that were on the top 35 instances (except lemmings.world which it couldn't grab any comments for.)