A sensor provides high-resolution tactile information so robots could better manipulate and grasp objects.

One key objective for scientists developing robots is to provide them with a sense of touch similar to that of humans so they can grasp and manipulate objects in a way that's appropriate to the objects' composition.
Researchers at Queen Mary University of London have developed a new low-cost sensor that can measure parameters directly that other sensors often don't take into consideration in order to achieve a higher measurement accuracy, they said.
"The L-3 F-TOUCH measures interaction forces directly through an integrated mechanical suspension structure with a mirror system achieving higher measurement accuracy and wider measurement range," he said. "The sensor is physically designed to decouple force measurements from geometry information. Therefore, the sensed three-axis force is immunized from contact geometry compared to its competitors."
Paper
L3 F-TOUCH: A Wireless GelSight With Decoupled Tactile and Three-Axis Force Sensing
Abstract
GelSight sensors that estimate contact geometry and force by reconstructing the deformation of their soft elastomer from images would yield poor force measurements when the elastomer deforms uniformly or reaches deformation saturation. Here we present an L 3 F-TOUCH sensor that considerably enhances the three-axis force sensing capability of typical GelSight sensors. Specifically, the L 3 F-TOUCH sensor comprises: (i) an elastomer structure resembling the classic GelSight sensor design for fine-grained contact geometry sensing; and (ii) a mechanically simple suspension structure to enable three-dimensional elastic displacement of the elastomer structure upon contact. Such displacement is tracked by detecting the displacement of an ARTag and is transformed to three-axis contact force via calibration. We further revamp the sensor's optical system by fixing the ARTag on the base and reflecting it to the same camera viewing the elastomer through a mirror. As a result, the tactile and force sensing modes can operate independently, but the entire L 3 F-TOUCH remains L ight-weight and L ow-cost while facilitating a wireless deployment. Evaluations and experiment results demonstrate that the proposed L 3 F-TOUCH sensor compromises GelSight's limitation in force sensing and is more practical compared with equipping commercial three-axis force sensors. Thus, the L 3 F-TOUCH could further empower existing Vision-based Tactile Sensors (VBTSs) in replication and deployment.
Researchers at Stanford Crack The Code of Natural Vision As New Model Reveals How Eyes Decode Visual Scenes
In a recent research paper, a group of researchers has made a significant advancement by showing that a three-layer network model is capable of predicting retinal responses to natural sceneries with amazing precision, almost exceeding the bounds of experimental data. The researchers wanted to understand how the brain processes natural visual scenes, so they focused on the retina, which is part of the eye that sends signals to the brain.
Paper
Interpreting the retinal neural code for natural scenes: From computations to neurons
Abstract
Understanding the circuit mechanisms of the visual code for natural scenes is a central goal of sensory neuroscience. We show that a three-layer network model predicts retinal natural scene responses with an accuracy nearing experimental limits. The model’s internal structure is interpretable, as interneurons recorded separately and not modeled directly are highly correlated with model interneurons. Models fitted only to natural scenes reproduce a diverse set of phenomena related to motion encoding, adaptation, and predictive coding, establishing their ethological relevance to natural visual computation. A new approach decomposes the computations of model ganglion cells into the contributions of model interneurons, allowing automatic generation of new hypotheses for how interneurons with different spatiotemporal responses are combined to generate retinal computations, including predictive phenomena currently lacking an explanation. Our results demonstrate a unified and general approach to study the circuit mechanisms of ethological retinal computations under natural visual scenes.
Emergence can be defined as the sudden appearance of novel behavior. Large Language Models apparently display emergence by suddenly gaining new abilities as they grow. Why does this happen, and what does this mean?

Language models (LMs) are a class of probabilistic models that learn patterns in natural language. LMs can be utilized for generative purposes to generate, say, the next event in a story by exploiting their knowledge of these patterns.
In recent years, significant efforts have been put into scaling LMs into Large Language Models (LLMs). The scaling process - training bigger models on more data with greater compute - leads to steady and predictable improvements in their ability to learn these patterns, which can be observed in improvements to quantitative metrics.
In addition to these steady quantitative improvements, the scaling process also leads to interesting qualitative behavior. As LLMs are scaled they hit a series of critical scales at which new abilities are suddenly “unlocked”. LLMs are not directly trained to have these abilities, and they appear in rapid and unpredictable ways as if emerging out of thin air. These emergent abilities include performing arithmetic, answering questions, summarizing passages, and more, which LLMs learn simply by observing natural language.
What is the cause of these emergent abilities, and what do they mean? In this article, we'll explore the concept of emergence as a whole before exploring it with respect to Large Language Models. We'll end with some notes about what this means for AI as a whole. Let's dive in!
Here is an Ars Technica article on the technology.
Paralyzed Patients Speak Again Thanks to AI-Powered Brain Implants
Efforts to restore speech to people silenced by brain injuries and diseases have taken a significant step forward with the publication of two new papers in the journal Nature.
In the work, two multidisciplinary teams demonstrated new records of speed and accuracy for state-of-the-art, AI-assisted brain-computer interface (BCI) systems. The advances point the way to granting people who can no longer speak the ability to communicate at near conversation-level pace and even show how that text can be retranslated into speech using computer programs that mimic the patient’s voice. One group developed a digital avatar that a paralyzed patient used to communicate with accurate facial gestures.
Paper
A high-performance speech neuroprosthesis
Abstract
Speech brain–computer interfaces (BCIs) have the potential to restore rapid communication to people with paralysis by decoding neural activity evoked by attempted speech into text1,2 or sound3,4. Early demonstrations, although promising, have not yet achieved accuracies sufficiently high for communication of unconstrained sentences from a large vocabulary1,2,3,4,5,6,7. Here we demonstrate a speech-to-text BCI that records spiking activity from intracortical microelectrode arrays. Enabled by these high-resolution recordings, our study participant—who can no longer speak intelligibly owing to amyotrophic lateral sclerosis—achieved a 9.1% word error rate on a 50-word vocabulary (2.7 times fewer errors than the previous state-of-the-art speech BCI2) and a 23.8% word error rate on a 125,000-word vocabulary (the first successful demonstration, to our knowledge, of large-vocabulary decoding). Our participant’s attempted speech was decoded at 62 words per minute, which is 3.4 times as fast as the previous record8 and begins to approach the speed of natural conversation (160 words per minute9). Finally, we highlight two aspects of the neural code for speech that are encouraging for speech BCIs: spatially intermixed tuning to speech articulators that makes accurate decoding possible from only a small region of cortex, and a detailed articulatory representation of phonemes that persists years after paralysis. These results show a feasible path forward for restoring rapid communication to people with paralysis who can no longer speak.

In “Language to Rewards for Robotic Skill Synthesis”, we propose an approach to enable users to teach robots novel actions through natural language input. To do so, we leverage reward functions as an interface that bridges the gap between language and low-level robot actions. We posit that reward functions provide an ideal interface for such tasks given their richness in semantics, modularity, and interpretability. They also provide a direct connection to low-level policies through black-box optimization or reinforcement learning (RL). We developed a language-to-reward system that leverages LLMs to translate natural language user instructions into reward-specifying code and then applies MuJoCo MPC to find optimal low-level robot actions that maximize the generated reward function. We demonstrate our language-to-reward system on a variety of robotic control tasks in simulation using a quadruped robot and a dexterous manipulator robot. We further validate our method on a physical robot manipulator.
Robust Quadrupedal Locomotion via Risk-Averse Policy Learning
Abstract
The robustness of legged locomotion is crucial for quadrupedal robots in challenging terrains. Recently, Reinforcement Learning (RL) has shown promising results in legged locomotion and various methods try to integrate privileged distillation, scene modeling, and external sensors to improve the generalization and robustness of locomotion policies. However, these methods are hard to handle uncertain scenarios such as abrupt terrain changes or unexpected external forces. In this paper, we consider a novel risk-sensitive perspective to enhance the robustness of legged locomotion. Specifically, we employ a distributional value function learned by quantile regression to model the aleatoric uncertainty of environments, and perform risk-averse policy learning by optimizing the worst-case scenarios via a risk distortion measure. Extensive experiments in both simulation environments and a real Aliengo robot demonstrate that our method is efficient in handling various external disturbances, and the resulting policy exhibits improved robustness in harsh and uncertain situations in legged locomotion.
Reinforced Self-Training (ReST) for Language Modeling
Abstract
Reinforcement learning from human feedback (RLHF) can improve the quality of large language model's (LLM) outputs by aligning them with human preferences. We propose a simple algorithm for aligning LLMs with human preferences inspired by growing batch reinforcement learning (RL), which we call Reinforced Self-Training (ReST). Given an initial LLM policy, ReST produces a dataset by generating samples from the policy, which are then used to improve the LLM policy using offline RL algorithms. ReST is more efficient than typical online RLHF methods because the training dataset is produced offline, which allows data reuse. While ReST is a general approach applicable to all generative learning settings, we focus on its application to machine translation. Our results show that ReST can substantially improve translation quality, as measured by automated metrics and human evaluation on machine translation benchmarks in a compute and sample-efficient manner.
The chip showcases critical building blocks of a scalable mixed-signal architecture.

IBM Research has been investigating ways to reinvent the way that AI is computed. Analog in-memory computing, or simply analog AI, is a promising approach to address the challenge by borrowing key features of how neural networks run in biological brains. In our brains, and those of many other animals, the strength of synapses (which are the “weights” in this case) determine communication between neurons. For analog AI systems, we store these synaptic weights locally in the conductance values of nanoscale resistive memory devices such as phase change memory (PCM) and perform multiply-accumulate (MAC) operations, the dominant compute operation in DNNs by exploiting circuit laws and mitigating the need to constantly send data between memory and processor.
Paper
Abstract
Analogue in-memory computing (AIMC) with resistive memory devices could reduce the latency and energy consumption of deep neural network inference tasks by directly performing computations within memory. However, to achieve end-to-end improvements in latency and energy consumption, AIMC must be combined with on-chip digital operations and on-chip communication. Here we report a multicore AIMC chip designed and fabricated in 14 nm complementary metal–oxide–semiconductor technology with backend-integrated phase-change memory. The fully integrated chip features 64 AIMC cores interconnected via an on-chip communication network. It also implements the digital activation functions and additional processing involved in individual convolutional layers and long short-term memory units. With this approach, we demonstrate near-software-equivalent inference accuracy with ResNet and long short-term memory networks, while implementing all the computations associated with the weight layers and the activation functions on the chip. For 8-bit input/output matrix–vector multiplications, in the four-phase (high-precision) or one-phase (low-precision) operational read mode, the chip can achieve a maximum throughput of 16.1 or 63.1 tera-operations per second at an energy efficiency of 2.48 or 9.76 tera-operations per second per watt, respectively.
The paper is really interesting, even though it looks like it was translated with Google Translate. I'm not sure as to the credibility of this particular institution, but the concept of using BOLD data to initiate the simulation is a really interesting one. I wonder if it would work better using data from the new sub-micron fMRI tech.
The really fascinating point is that they were able to check the simulation but giving it inputs similar to what a live brain would receive, and get very similar responses. That's amazing, and I'd like to see if anyone else manages to replicate their results.
Digital Twin Brain: a simulation and assimilation platform for whole human brain
Abstract
In this work, we present a computing platform named digital twin brain (DTB) that can simulate spiking neuronal networks of the whole human brain scale and more importantly, a personalized biological brain structure. In comparison to most brain simulations with a homogeneous global structure, we highlight that the sparseness, couplingness and heterogeneity in the sMRI, DTI and PET data of the brain has an essential impact on the efficiency of brain simulation, which is proved from the scaling experiments that the DTB of human brain simulation is communication-intensive and memory-access-intensive computing systems rather than computation-intensive. We utilize a number of optimization techniques to balance and integrate the computation loads and communication traffics from the heterogeneous biological structure to the general GPU-based HPC and achieve leading simulation performance for the whole human brain-scaled spiking neuronal networks. On the other hand, the biological structure, equipped with a mesoscopic data assimilation, enables the DTB to investigate brain cognitive function by a reverse-engineering method, which is demonstrated by a digital experiment of visual evaluation on the DTB. Furthermore, we believe that the developing DTB will be a promising powerful platform for a large of research orients including brain-inspired intelligence, rain disease medicine and brain-machine interface.
This still needs independent verification, but would be world-changing if true.
Possible Room-Temperature Ambient-Pressure Superconductor
Abstract
For the first time in the world, we succeeded in synthesizing the room-temperature superconductor (Tc≥400 K, 127∘C) working at ambient pressure with a modified lead-apatite (LK-99) structure. The superconductivity of LK-99 is proved with the Critical temperature (Tc), Zero-resistivity, Critical current (Ic), Critical magnetic field (Hc), and the Meissner effect. The superconductivity of LK-99 originates from minute structural distortion by a slight volume shrinkage (0.48 %), not by external factors such as temperature and pressure. The shrinkage is caused by Cu2+ substitution of Pb2+(2) ions in the insulating network of Pb(2)-phosphate and it generates the stress. It concurrently transfers to Pb(1) of the cylindrical column resulting in distortion of the cylindrical column interface, which creates superconducting quantum wells (SQWs) in the interface. The heat capacity results indicated that the new model is suitable for explaining the superconductivity of LK-99. The unique structure of LK-99 that allows the minute distorted structure to be maintained in the interfaces is the most important factor that LK-99 maintains and exhibits superconductivity at room temperatures and ambient pressure.
https://doi.org/10.48550/arXiv.2307.12008
On July 12, 2023, a new research paper was published in Aging, titled, “Chemically induced reprogramming to reverse cellular aging.”
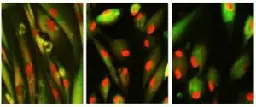
In a groundbreaking study, researchers have unlocked a new frontier in the fight against aging and age-related diseases. The study, conducted by a team of scientists at Harvard Medical School, has published the first chemical approach to reprogram cells to a younger state. Previously, this was only achievable using a powerful gene therapy.
Journal Article
Chemically induced reprogramming to reverse cellular aging
Abstract:
A hallmark of eukaryotic aging is a loss of epigenetic information, a process that can be reversed. We have previously shown that the ectopic induction of the Yamanaka factors OCT4, SOX2, and KLF4 (OSK) in mammals can restore youthful DNA methylation patterns, transcript profiles, and tissue function, without erasing cellular identity, a process that requires active DNA demethylation. To screen for molecules that reverse cellular aging and rejuvenate human cells without altering the genome, we developed high-throughput cell-based assays that distinguish young from old and senescent cells, including transcription-based aging clocks and a real-time nucleocytoplasmic compartmentalization (NCC) assay. We identify six chemical cocktails, which, in less than a week and without compromising cellular identity, restore a youthful genome-wide transcript profile and reverse transcriptomic age. Thus, rejuvenation by age reversal can be achieved, not only by genetic, but also chemical means.
MIT CSAIL researchers created FrameDiff, a computational tool utilizing machine learning to design novel protein structures. By simulating protein backbones with mathematical frames, FrameDiff constructs proteins that surpass natural varieties.
To advance our capabilities in protein engineering, MIT CSAIL researchers came up with “FrameDiff,” a computational tool for creating new protein structures beyond what nature has produced. The machine learning approach generates “frames” that align with the inherent properties of protein structures, enabling it to construct novel proteins independently of preexisting designs, facilitating unprecedented protein structures.
Journal Link
SE(3) diffusion model with application to protein backbone generation
Github Link
SE(3) diffusion model with application to protein backbone generation
DNA crystal engineering makes logic gates possible, which could lead to DNA-based computers and biosensors.
Researchers have successfully realized logic gates using DNA crystal engineering, a monumental step forward in DNA computation. Their findings were published in Advanced Materials. Using DNA double crossover-like motifs as building blocks, they constructed complex 3D crystal architectures. The logic gates were implemented in large ensembles of these 3D DNA crystals, and the outputs were visible through the formation of macroscopic crystals. This advancement could pave the way for DNA-based biosensors, offering easy readouts for various applications. The study demonstrates the power of DNA computing, capable of executing massively parallel information processing at a molecular level, while maintaining compatibility with biological systems.
Journal Article
Implementing Logic Gates by DNA Crystal Engineering
Abstract:
DNA self-assembly computation is attractive for its potential to perform massively parallel information processing at the molecular level while at the same time maintaining its natural biocompatibility. It has been extensively studied at the individual molecule level, but not as much as ensembles in 3D. Here, the feasibility of implementing logic gates, the basic computation operations, in large ensembles: macroscopic, engineered 3D DNA crystals is demonstrated. The building blocks are the recently developed DNA double crossover-like (DXL) motifs. They can associate with each other via sticky-end cohesion. Common logic gates are realized by encoding the inputs within the sticky ends of the motifs. The outputs are demonstrated through the formation of macroscopic crystals that can be easily observed. This study points to a new direction of construction of complex 3D crystal architectures and DNA-based biosensors with easy readouts.
Buck Scientists develop specific, bioavailable compound that prevents and treats metabolic syndrome in mice – and they've put it in a pill.
Back in 1956, Denham Harman proposed that the aging is caused by the build up of oxidative damage to cells, and that this damage is caused by free radicals which have been produced during aerobic respiration [1]. Free radicals are unstable atoms that have an unpaired electron, meaning a free radical is constantly on the look-out for an atom that has an electron it can pinch to fill the space. This makes them highly reactive, and when they steal atoms from your body’s cells, it is very damaging.
Journal Article
A reliable digital bridge restored communication between the brain and spinal cord and enabled natural walking in a participant with spinal cord injury.
Abstract
A spinal cord injury interrupts the communication between the brain and the region of the spinal cord that produces walking, leading to paralysis. Here, we restored this communication with a digital bridge between the brain and spinal cord that enabled an individual with chronic tetraplegia to stand and walk naturally in community settings. This brain–spine interface (BSI) consists of fully implanted recording and stimulation systems that establish a direct link between cortical signals and the analogue modulation of epidural electrical stimulation targeting the spinal cord regions involved in the production of walking. A highly reliable BSI is calibrated within a few minutes. This reliability has remained stable over one year, including during independent use at home. The participant reports that the BSI enables natural control over the movements of his legs to stand, walk, climb stairs and even traverse complex terrains. Moreover, neurorehabilitation supported by the BSI improved neurological recovery. The participant regained the ability to walk with crutches overground even when the BSI was switched off. This digital bridge establishes a framework to restore natural control of movement after paralysis.
MSU develops brain imaging system to reveal how memories are made, recorded
“We want to know how memories are made and how they fail to be made in people with memory disorders like Alzheimer’s disease,” said Mark Reimers, an associate professor in the College of Natural Science and Institute for Quantitative Health Sciences and Engineering. “We’d like to investigate and track the evolution of a memory over time and even observe how things get mixed up in everyday memory.”
Currently, high-resolution brain imaging techniques can capture only a few hundred individual neurons — the nerve cells that transmit electrical signals throughout the body — at a time. Starting with some initial seed money from the director of IQHSE, Christopher Contag, and MSU’s neuroscience program, Reimers and his co-investigator Christian Burgess at the University of Michigan were able to develop a prototype of the imaging system that has the potential to image 10,000 to 20,000 neurons, giving researchers an unprecedented view of brain activity in real time while it is making and recalling memories. This research has led to a three-year $750,000 grant from the Air Force Office of Scientific Research.
NeuWS: Neural wavefront shaping for guidestar-free imaging through static and dynamic scattering media
Abstract
Diffraction-limited optical imaging through scattering media has the potential to transform many applications such as airborne and space-based imaging (through the atmosphere), bioimaging (through skin and human tissue), and fiber-based imaging (through fiber bundles). Existing wavefront shaping methods can image through scattering media and other obscurants by optically correcting wavefront aberrations using high-resolution spatial light modulators—but these methods generally require (i) guidestars, (ii) controlled illumination, (iii) point scanning, and/or (iv) statics scenes and aberrations. We propose neural wavefront shaping (NeuWS), a scanning-free wavefront shaping technique that integrates maximum likelihood estimation, measurement modulation, and neural signal representations to reconstruct diffraction-limited images through strong static and dynamic scattering media without guidestars, sparse targets, controlled illumination, nor specialized image sensors. We experimentally demonstrate guidestar-free, wide field-of-view, high-resolution, diffraction-limited imaging of extended, nonsparse, and static/dynamic scenes captured through static/dynamic aberrations.
50 million synapses? A simulation at that scale should actually work on your average modern gaming PC; perhaps a bit slowly, depending on how much VRAM you have, and how the vector calculations are computed.
A whole-brain connectome of the fruit fly, including ~130k annotated neurons and tens of millions of typed synapses
Announcement via Twitter
Papers:
Neuronal diagram of an adult (fruit fly) brain
Explore the connectome: https://codex.flywire.ai
Paper page - HyenaDNA: Long-Range Genomic Sequence Modeling at Single Nucleotide Resolution
Join the discussion on this paper page
Abstract
Genomic (DNA) sequences encode an enormous amount of information for gene regulation and protein synthesis. Similar to natural language models, researchers have proposed foundation models in genomics to learn generalizable features from unlabeled genome data that can then be fine-tuned for downstream tasks such as identifying regulatory elements. Due to the quadratic scaling of attention, previous Transformer-based genomic models have used 512 to 4k tokens as context (<0.001% of the human genome), significantly limiting the modeling of long-range interactions in DNA. In addition, these methods rely on tokenizers to aggregate meaningful DNA units, losing single nucleotide resolution where subtle genetic variations can completely alter protein function via single nucleotide polymorphisms (SNPs). Recently, Hyena, a large language model based on implicit convolutions was shown to match attention in quality while allowing longer context lengths and lower time complexity. Leveraging Hyenas new long-range capabilities, we present HyenaDNA, a genomic foundation model pretrained on the human reference genome with context lengths of up to 1 million tokens at the single nucleotide-level, an up to 500x increase over previous dense attention-based models. HyenaDNA scales sub-quadratically in sequence length (training up to 160x faster than Transformer), uses single nucleotide tokens, and has full global context at each layer. We explore what longer context enables - including the first use of in-context learning in genomics for simple adaptation to novel tasks without updating pretrained model weights. On fine-tuned benchmarks from the Nucleotide Transformer, HyenaDNA reaches state-of-the-art (SotA) on 12 of 17 datasets using a model with orders of magnitude less parameters and pretraining data. On the GenomicBenchmarks, HyenaDNA surpasses SotA on all 8 datasets on average by +9 accuracy points.
Robots are quickly becoming part of our everyday lives, but they’re often only programmed to perform specific tasks well. While harnessing recent advances in AI could lead to robots that could help in many more ways, progress in building general-purpose robots is slower in part because of the time n...
New foundation agent learns to operate different robotic arms, solves tasks from as few as 100 demonstrations, and improves from self-generated data.
Robots are quickly becoming part of our everyday lives, but they’re often only programmed to perform specific tasks well. While harnessing recent advances in AI could lead to robots that could help in many more ways, progress in building general-purpose robots is slower in part because of the time needed to collect real-world training data.
Our latest paper introduces a self-improving AI agent for robotics, RoboCat, that learns to perform a variety of tasks across different arms, and then self-generates new training data to improve its technique.
Previous research has explored how to develop robots that can learn to multi-task at scale and combine the understanding of language models with the real-world capabilities of a helper robot. RoboCat is the first agent to solve and adapt to multiple tasks and do so across different, real robots.
RoboCat learns much faster than other state-of-the-art models. It can pick up a new task with as few as 100 demonstrations because it draws from a large and diverse dataset. This capability will help accelerate robotics research, as it reduces the need for human-supervised training, and is an important step towards creating a general-purpose robot
Basic summary:
This is a scan of a whole mouse brain at a resolution that enables the reading of individual synapses, thus enabling a connectome map to be created for a whole individual's brain. The process, named HiDiver, is currently being planned for use on individual human brains in the future.
Are these the hot spots that lead to the storm, or the storm track itself?
Okay, before I head off to bed, I think this works for the login and authentication token:
import requests
import json
def login(username_or_email, password):
# Define the URL for the login endpoint
url = "https://lemmy.ml/api/v1/user/login"
# Define the headers for the request
headers = {'Content-Type': 'application/json'}
# Define the data for the login
data = {
"username_or_email": username_or_email,
"password": password
}
# Send the POST request
response = requests.post(url, headers=headers, data=json.dumps(data))
# Extract the JWT from the response
jwt = response.json().get('jwt')
return jwt
# Use the login function
jwt = login("your_username_or_email", "your_password")
print(jwt)
The JSON Web Token (jwt) should contain the authentication token. At least I think that's the case. I picked this out by reading through the Go code at the following URL: https://github.com/Elara6331/go-lemmy/blob/master/lemmy.go
I'll play around with the code later.
Here's another example, this time for creating a comment:
import requests
import json
# Define the URL for the API endpoint
url = "https://lemmy.ml/api/v1/comment"
# Define the headers for the request
headers = {'Content-Type': 'application/json'}
# Define the data for the new comment
data = {
"content": "Your comment content",
"post_id": 123, # Replace with the ID of the post you're commenting on
"form_id": "your_form_id", # Replace with your form ID
"auth": "your_auth_token_here"
}
# Send the POST request
response = requests.post(url, headers=headers, data=json.dumps(data))
# Print the response
print(response.json())
Does anyone know how to do the login process in Lemmy, and retrieve an auth token?