Linguistics
-
Where can I find all the scanned copies for the Tulu Lexicon?
I've tried looking for this project all over Libgen, Internet Archive and similar sites, but could not find it anywhere. I was only able to come across a Reddit post with the physical copies of the book.
-
Systematic testing of three Language Models reveals low language accuracy, absence of response stability, and a yes-response bias
Interesting paper, about the alleged ability of LLMs\* to judge the grammaticality of sentences - something that humans are rather good at. Eight phenomena were tested, and LLMs performed extremely poorly.
\*LLM = large language model. Stuff like Bard, ChatGPT, LLaMa etc. I'd argue that they aren't actual language models due to the absence of a semantic component, as shown by the article.
-
Small Discussions #1 (2023/Dec/01)
I'm creating this thread to hopefully promote a bit more activity in the community.
If you want to talk about something Linguistics-related, but for some reason you don't want to create a new post just for that, feel free to post it here instead.
-
Introduction to Linguistics
cross-posted from: https://slrpnk.net/post/4507295
> Institution: MIT > Lecturer: Prof. Norvin A. Richards > University Course Code: MIT 24.900 > Subject: #linguistics > Description: > This class provides some answers to basic questions about the nature of human language. Throughout the course, we examine a number of ways in which human language is a complex but law-governed mental system. Much of the class is devoted to studying some core aspects of this system in detail; we also spend individual classes discussing a number of other issues, including how language is acquired, how languages change over time, language endangerment, and others.
-
Language and Poverty
Even if not solid research, I think that this article is worth sharing as food for though.
The author mentions Duncan's five faces of poverty (material, social, spiritual, aspirational and identity), then focuses on the later two, and proposes that language also plays a role in social poverty.
Superficially it might seen that the author proposes "replacive bilingualism" (i.e. linguicide) as a solution for this problem; he doesn't, he is mentioning it to highlight how individuals seek to address this linguistic poverty.
Make sure to give a check to the references cited - there's a lot of good stuff there.
- news.mit.edu How “blue” and “green” appeared in a language that didn’t have words for them
A new study suggests the way a language divides up color space can be influenced by contact with other languages. Tsimane’ people who learned Spanish as a second language began to classify blue and green into using separate words, which their native tongue does not do.

The article shows a case of language contact (Tsimané vs. Spanish) triggering the conceptual split of a colour into two.
- thereader.mitpress.mit.edu The Role of Myth in Language: From Lingua Adamica to Babel
Linguist Marina Yaguello traces the myths, legends, and religious narratives that have shaped humanity's understanding of the origins of language.

- www.bbc.com The surprisingly subtle ways Microsoft Word has changed how we use language
As Microsoft Word turns 40, we look at the role the software has played in four decades of language and communication evolution.
- theconversation.com Indo-European Languages: New Study Reconciles Two Dominant Hypotheses About Their Origin
Using data from over 160 languages, a new study explains where, when and how Indo-European languages spread across Europe and Asia.

The languages in the Indo-European family are spoken by almost half of the world’s population. This group includes a huge number of languages, ranging from English and Spanish to Russian, Kurdish and Persian.
Ever since the discovery, over two centuries ago, that these languages belong to the same family, philologists have worked to reconstruct the first Indo-European language (known as Proto-Indo-European) and establish a “language family tree”, where branches represent the evolution and separation of languages over time. This approach draws on phylogenetics – the study of how biological species evolve – which also provides the most appropriate model for describing and quantifying the historical relationships between languages.
Despite numerous studies, many questions still remain as to the origin of Indo-European: where was the original Indo-European language spoken in prehistoric times? How long ago did this language group emerge? How did it spread across Eurasia?
-
Italians have embraced ‘fake English’
Fluency in ‘inglese farlocco’ has become necessary in Italy as hybrid words and off-kilter meanings proliferate.
- phys.org Have you heard about the 'whom of which' trend?
Back in the spring of 2022, professor of linguistics David Pesetsky was talking to an undergraduate class about relative clauses, which add information to sentences. For instance: "The senator, with whom we were speaking, is a policy expert." Relative clauses often feature "who," "which," "that," an...

As Evile and Pesetsky show in a newly published paper, "whom of which" obeys very specific rules, whose nature contributes to a larger discussion about sentence construction. The paper, "Wh-which relatives and the existence of pied piping," appears this month in the journal Glossa.
"It seems to be brand new, and it's very colloquial, but it's extremely law-governed," says Pesetsky, the Ferrari P. Ward Professor of Modern Languages and Linguistics at MIT.
-
Local difference in pronunciation -- northern IN. Back me up here??
I was discussing this with my fiance, and she agreed with me in that she also speaks English in this manner.
I have found that, at least personally, I tend to speak several common homonyms in English in distinct ways: bear/bare, they're/there, where/ware. It's difficult to describe the differences in a concise way, but I'll do my best, and maybe use IPA where applicable, assuming I'm not using them incorrectly?
The traditional pronunciation of bare is [ˈbɛr]. I would completely agree with this, and while the dictionary might also say bear is pronounced this way, I would argue that I often hear it more as [ˈber] — a more closed sound with the lips pulled back in a smile. Sure, sometimes people will lazily say both in the same manner, but if I say [ˈber], the listener is going to recognize in a vacuum that I am speaking of the furry mammal, not the term to describe a naked person.
Similarly, there is rendered as [ðɚ]. There is a perfect rhyme with bare. I agree with this. However, they're is given the treatment of being a contraction of "they are", and it similarly has that closed sounded [e] instead of [ə].
Am I crazy, or does anyone else out there experience English this way?
- www.newsweek.com Archaeologists discover previously unknown language from ancient tablet
The recently discovered language remains largely incomprehensible, but researchers said it belongs to the Indo-European family.

without the filler:
>Excavations have been taking place at Boğazköy-Hattusha for more than century under the direction of the German Archaeological Institute (DAI).
>Around 30,000 clay tablets have been found at the site to date, which have shed light on various aspects of life during the Hittite period, according to the Julius-Maximilians-Universität Würzburg. The tablets contain inscriptions in cuneiform—what is generally considered to be the oldest known writing system. Developed by the ancient Sumerians of Mesopotamia more than 5,000 years ago, cuneiform is a script that was used to write several languages of the ancient Near East.
>Most of the inscriptions found at Boğazköy-Hattusha record the extinct Hittite language, which is the oldest attested member of the Indo-European family. Other languages, such as Luwian and Palaic, are also represented at the site.
>However, excavations conducted this year, led by professor Dr. Andreas Schachner of the DAI's Istanbul Department, surprisingly uncovered a recitation of a previously unknown extinct language. The language was hidden on a cuneiform tablet containing a ritual text written in Hittite. The Hittite ritual text refers to the lost tongue as the language of the land of Kalašma, an area that likely corresponds to where the towns of Bolu or Gerede in northern Turkey are located today.
>"The new language was written in cuneiform," Schachner told Newsweek. "It is the same writing system the Hittites used. The text is part of a longer text starting in Hittite. As it continues it says at one point: 'Continue in the language of the Land [of] Kalašma.'"
>"The Hittites were uniquely interested in recording rituals in foreign languages," Daniel Schwemer, head of the Chair of Ancient Near Eastern Studies at Julius-Maximilians-Universität Würzburg, said in a press release.
>The recently discovered language remains largely incomprehensible. However, Professor Elisabeth Rieken with the Philipps University of Marburg, Germany, a specialist in Anatolian languages, has confirmed that the Kalasmaic tongue belongs to the Indo-European family, according to Julius-Maximilians-Universität Würzburg.
EDIT: a more readable article with some other details here - https://www.uni-wuerzburg.de/en/news-and-events/news/detail/news/new-indo-european-language-discovered/
-
How We Know Languages like Proto-Indo-European Existed
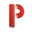
This video offers a nice introduction on the comparative method, used to reconstruct languages without direct attestation, and then talks a bit about the reconstruction of Proto-Indo-European. It's full of examples and rather accessible, even for people not well-versed in Historical Linguistics (or even Linguistics).
-
Societies of strangers do not speak less complex languages
It's sometimes claimed that languages spoken by societies with large numbers of non-native speakers, and large heterogeneity of their native speakers, tend to simplify themselves over time. This study contradicts the claim, based on data for morphological complexity from 1k+ languages.
- www.iflscience.com Scientists Witnessed The Birth Of A New Accent In Antarctica
Could a Martian accent be next?

-
„She knows her semantics“: Excessive use of posessive pronouns in English
Phrases like know one's \[general subject of interest\] are very annoying to me because they seem rather self-centered. I am obviously fine with knows his way around or Know Your Customer because the use of possesive pronouns is appropriate. On the other hand, now I know my ABCs is atrocious because the modern Latin alphabet obviously does not and never did belong to a single person, and has been used by billions of people in the last few centuries.
Do you know other English phrases with unnecessary posessive or personal pronouns? Do they exist in other languages? Is there a name for this linguistic phenomenon? Where do I complain? /s
-
New insights into the origin of the Indo-European languages
www.mpg.de New insights into the origin of the Indo-European languagesLinguistics and genetics combine to suggest a new hybrid hypothesis for the origin of the Indo-European languages
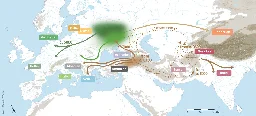
The study involved linguists and geneticists, and estimated the family to be around 8100 years old, with five main branches splitting off 7000 years ago or so. That fits neither the Kurgan/Steppe hypothesis nor the farming/Anatolian one. Instead the authors propose a hybrid hypothesis, with PIE spreading initially from the southern Caucasus; and then an IE branch going north, into the steppes, and spreading from there.
Personal note: that further hints that the similarities noticed between the NW Caucasian languages and the current PIE reconstructions aren't just a result of coincidence; they might be areal features. I wouldn't be surprised for example if what's currently reconstructed as \*e \o was originally vertical, something like \\ə \\*a (Ubykh style).
-
Why was writing invented so few times throughout history?
From what I’ve seen, writing was independently invented somewhere between 3 to 6 times. With so many languages and linguistic communities, why have so few independently invented writing?
-
Combining Maths and Linguistics with Category Theory
blog.juliosong.com A new application of category theory in linguistics (part 1)This is the second part of my “portfolio” prepared for the virtual poster session at ACT2020. It introduces my category-theoretic modeling of the human language grammatical type (aka syntactic category) system. The technical detail can be found in my dissertation “On the formal flexibility of syntac...

I'm a mathsy scientist, not a linguist, so I'm coming at this from a different angle, but I find this blog by a linguist gives a great informal overview of applied category theory in linguistics.
Similar concepts from a mathematician's angle is here: https://www.math3ma.com/blog/language-statistics-category-theory-part-1 I really enjoy how complementary these perspectives are
-
Global predictors of language endangerment and the future of linguistic diversity
www.nature.com Global predictors of language endangerment and the future of linguistic diversity - Nature Ecology & EvolutionUsing a global analysis of 6,511 spoken languages with 51 predictor variables spanning aspects of population, documentation, legal recognition, education policy, socioeconomic indicators and environmental features, the authors identify predictors of current and future language endangerment and loss.
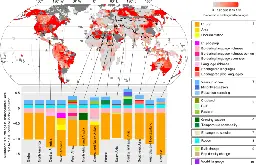
The article provides a global analysis to model patterns of current and future language endangerment. In other words, it's trying to explain and predict where and how language loss happens, by measuring stuff.
Interesting excerpts of the article:
>Our best-fit model explains 34% of the variation in language endangerment (comparable to similar analyses on species endangerment.
That's actually rather good, considering the global scale of analysis for something as messy as human beings, and how local political factors can revive or kill languages.
>Five predictors of language endangerment are consistently identified at global and regional scales: L1 speakers, bordering language richness, road density, years of schooling and the number of endangered languages in the immediate neighbourhood.
I feel like linguists handling minority languages should already know thing by "gut feeling": small community, with lots of nearby languages, well-connected to other communities, being drilled by the government = threatened linguistic community. However, it's still great that the article is grounding that "gut feeling" into data.
-
Genes and languages aren't always found together, says new study
phys.org Genes and languages aren't always found together, says new studyMore than 7,000 languages are spoken in the world. This linguistic diversity is passed on from one generation to the next, similarly to biological traits. But have language and genes evolved in parallel over the past few thousand years, as Charles Darwin originally thought?
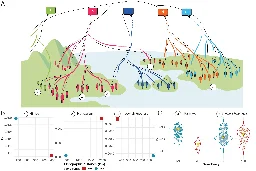
Link for the study: A global analysis of matches and mismatches between human genetic and linguistic histories
The conclusion itself is nothing new, but there are some interesting tidbits, such as about 1/5 of the gene-language relations being a mismatch.
-
A Partial Decipherment of the Unknown Kushan Script
It's a script attested from 2200~1700 years old inscriptions found in Central Asia, between what's today Kazakhstan and Afghanistan (both included). Discovered in the 1950s, but now freshly discovered inscriptions from Tajikistan (the Almosi inscriptions) encouraged people to take a further look at the decipherment, alongside older inscriptions (such as the Dašt-i Nāwur trilingual; written in Greek, Bactrian, and the unknown script).
This is specially interesting for those interested on Tocharian studies, as the language being deciphered might be potentially spoken by Tocharian speakers who migrated south.
- scitechdaily.com Language and Stroke – Scientists Uncover Surprising Connection
Research indicates that Mexican Americans experience less favorable outcomes post-stroke compared to their non-Hispanic white American counterparts. A recent study delves into the potential correlation between the language spoken by Mexican Americans and their recovery trajectory following a stroke.
“Our study found that Mexican American people who spoke only Spanish had worse neurologic outcomes three months after having a stroke than Mexican American people who spoke only English or were bilingual ..."
-
Why linguists believe in invisible words - the story of zeros
Caution is advised when watching this video, as not all linguists buy the idea of zero morphemes/phonemes/etc.; for some the zero is just a neat theoretical trick, as it simplifies some descriptions. And some outright avoid the concept.
Even then, I feel like this video should be fairly informative and enjoyable for people in general.
-
Geoff Lindsey: Why William and Harry's accents are so different from King Charles's
King Charles speaks with a rather posh Received Pronunciation, much like Queen Elizabeth II did. In the meantime, William and Harry use a more Standard Southern British pronunciation.
The changes described by Lindsey can be summed up as:
- PRICE - [aɪ] vs. [ɑɪ]
- DRESS - [e] vs. [ɛ]
- CHOICE - [ɔɪ] vs. [oɪ]
- SQUARE - [ɛə] vs. [ɛ:]
- HAPPY - [ɪ] vs. [i]
- [ɫ] vocalisation, colouring nearby vowels - negligible vs. noticeable
- word ending /t/ - [t] vs. [ʔ]
- /t/ flapping into [ɾ] - rare vs. more frequent
- /t/ before front high vowel affricating into [ts] - actually attested for both sides
- unstressed syllable elision - King Charles did this quite a bit before rising to the throne, but William does it all the time
- rising intonation on statements (uptalk) - almost non-existent in RP, fairly common in SSB
- /θ/ as [f] - avoided in RP, present in SSB
- word ending /k/ as [k'] - avoided [?] vs. common
Personal observation: the changes in the vowel sets remind me in spirit the Great Vowel Shift, as it seems that DRESS lowering is pressing PRICE to go back, and in turn PRICE is forcing CHOICE to raise.
-
Comparison of fake and real news based on morphological analysis
This paper describes an IMO rather interesting approach towards fake news, through their morphological content: the words from each piece of news (real and fake) were grouped into categories, then the researchers made a statistical analysis of the usage of those categories in real and fake news. And they found out that:
- fake news tend to use more foreign words, adjectives and nouns
- real news tend to use more W-words (who, what), determiners, prepositions and verbs
I think that their findings are damn useful. Perhaps not to detect fake news, but to understand how they work on a discursive level. For example, the usage of foreign words in fake news caught my attention - perhaps they're used to mask the underlying meaning of the utterance? While real news are focused on describing events, and thus rely more on verb usage?
-
Glossika Phonics - a YT channel that shows detailed sound production
This will probably interest people who are just tipping their toes into Phonetics, as well as language leaners.
-
Universal linguistic hierarchies are not innately wired. Evidence from multiple adjectives
www.ncbi.nlm.nih.gov Universal linguistic hierarchies are not innately wired. Evidence from multiple adjectivesLinguists and psychologists have explained the remarkable similarities in the orderings of linguistic elements across languages by suggesting that our inborn ability for language makes available certain innately wired primitives. Different types of adjectives, ...

There's a general tendency across languages to order the adjectives connected to the same noun the same way; for example, usually adjectives referring to colour or other innate attributes are closer to the noun than the ones dealing with subjective attributes. This tendency is so strong that made some linguists (and psychologists) believe that this order might be actually innate.
This study contradicts that. Excerpt from the conclusion:
>Taking these findings together, we have argued that there is no universal hierarchy for adjective ordering imposing a hard constraint which then translates into one rigid, unmarked order.
-
To *b or not to *b: Proto-Indo-European *b in a phylogenetic perspective
Fun scientific paper talking about the odd rarity of \*b in the current Proto-Indo-European reconstructions. It doesn't propose why this happens, but it claims that most PIE instances of \*b might be actually from a later stage of the language, that the author calls "Indo-Celtic" (the common ancestor of all IE languages minus Anatolian and Tocharian; also known in the literature as "core PIE").
-
Non serious Linguistics community: Linguistics Humor
Hello ! Just find out (and subscribed to) this Linguisitics community existed (wasn't referenced in sh.itjust.works before today)
For information, few days ago, I created a Liguistics Humor community, to talk non seriously about linguistics subjects.
Link is here:
- For Lemmy users: [email protected]
- For kbin users: /m/[email protected]
- Direct instanciated link (if above does not works for you): https://sh.itjust.works/c/linguistics_humor
- Remember if you get a 404 page, to first go search for the community on your instance search page:
https://sh.itjust.works/c/linguistics_humor, after that, links should work
Rules here says to "Avoid crack theories and pseudoscientific claims"; on linguistics humor, that will be allowed !
On the other side, talking seriously will not be allowed, and will be redirected here (I've added a link to this community in the description)
Feel free to participate (and ask/suggest anything about it)
-
For fun: 2022 International Linguistics Olympiad
Those puzzles are fun to solve, so why not give them a try? Feel free to use this post to share hints or the solution as you've found it, but please use spoilers to do so.
The first three puzzles boil down to "retro-engineering" tidbits of the the grammar of three languages (Ubyx, Alabama, N|uuki). The fourth one is to deduce the words for familiar relationship used in Arabana. The fifth one is historical linguistics, deducing the sound changes from Proto-Chamic to Phan Rang Cham and Tsat.
Check this link for the puzzles of previous years, solutions, as well as versions in other metalanguages (in case you feel more comfortable solving them in another language than English).
-
Sound–meaning association biases evidenced across thousands of languages
This paper provides some actual data on the bouba-kiki effect, where certain words are non-arbitrarily associated with certain meanings, by analysing the frequency of sounds used in words conveying a specific meaning (as "bone", "stone", etc.). It takes cognates and areal effects into account.
-
Ian Maddieson - Patterns of Sounds (1984)
www.docdroid.net Maddieson 1984. Patterns of Sounds.pdfCambridge Studies in Speech Science and Communication Advisory Editorial Board J. Laver (Executive editor) A. J. Fourcin J. Gilbert M. Haggard P. Ladefoged B. Lindblom J. C. Marshall. Patterns of sounds. In this series: The phonetic bases of speaker recognition Francis Nolan. ...

This book lists cross-linguistic tendencies in phonetic inventories. It's a bit old, but a good read for anyone who:
- is into Phonetics and Phonology;
- wants to analyse the underlying pressures behind phonetic inventories (e.g. "why does language A have the sound X, instead of Y?")
- is building one's one constructed language, under a naturalistic approach
-
How the Unabomber’s unique linguistic fingerprints led to his capture
theconversation.com How the Unabomber's unique linguistic fingerprints led to his captureSimilar techniques used to identify criminals have been employed to unmask anonymous authors. But they aren’t foolproof.

In the light of Unabomber's passing away in prison, people are reviewing how he was captured, and how linguistics played a role on this.
Linguistic analysis of his Manifesto yielded the following pieces of info:
- "rearing children" - typical for a Northern USA dialect
- "clew", "wilfully" - back then, used mostly around Chicago; so the author likely spent his formative years around the place
- "broad", "chick" - narrowing down the expected age range to middle-aged
- "anomic", "chimerical" - highly educated speaker
The article also mentions a few other cases of linguistic analysis being used to identify other people, such as JK Rowling as the Cuckoo's Nest author.
-
This Ancient Language Has the Only Grammar Based Entirely on the Human Body
www.scientificamerican.com This Ancient Language Has the Only Grammar Based Entirely on the Human BodyAn endangered language family suggests that early humans used their bodies as a model for reality

The title is click-baity (e.g. what's an "ancient language"?), but the content is still interesting regardless.
A few highlights:
Acc. to the author Great Andamanese ("GA") speakers have been culturally isolated from speakers of other languages for millenniums. It has been described as a dialect continuum, but it's being replaced by Hindi and showing clear signs of language death.
What's unusual about its usage of body parts in the grammar is not the usage itself, but its frequency and how it does it. Excerpts from the article:
>If the blood emerged from the feet or legs, it was otei; internal bleeding was etei; and a clot on the skin was ertei. Something as basic as a noun changed form depending on location.
>My breakthrough was to realize that the prefix e-, which originally derived from an unknown word for an internal body part, had over eons morphed into a grammatical marker signifying any internal attribute, process or activity. So the act of seeing, ole, being an internal activity, had to be eole. The same prefix could be attached to -bungoi, or “beautiful,” to form ebungoi, meaning internally beautiful or kind; to sare, for “sea,” to form esare, or “salty,” an inherent quality; and to the root word -biinye, “thinking,” to yield ebiinye, “to think.”
-
Early Indo-European Online Lessons
This should be a great resource for beginners interested on Historical Linguistics, specially Indo-European studies. Each "lesson" provides a few pieces of information about either one Indo-European language, focusing mostly on historical and cultural information, but they provide a lot of links for people willing to understand one or more languages better.
(And yes, the banner of this community was proudly stolen from that page.)
-
(Andrew Garrett) On the origin of auxiliary "do" in English
This paper is '98 and it contrasts the then prevailing theories, in contrast with dialectal and historical evidence, arguing that the origin of periphrastic "do" was a habitual aspect marker.
Two of the earlier hypotheses that the author addresses and criticise:
Contact with Celtic languages - the feature would be borrowed from other languages that English interacted with. Specially prominent due to distribution, as do-periphrasis appeared first on the Western dialects. However unlikely, given that Celtic substratum influence in English was relatively minor.
Some invoke more complex pathways, such as a potential early Germanic-Celtic creolisation; the author claims that this is unattested.
Causative 'do' - occasionally attested in Old English, and frequently in Middle English. I'll adapt the 5a example to highlight the construction:
- I do to-you know[=witan]... that those devil-idols to-you are harm-bearing
Here the usage of "do" would initially mean something like "make", "cause to", "have". For another example [from my own], consider "I did her tell me what was going on" - the "do" has some meaning but it's rather messy, and dependent on the sentence. (Does that "did" mean "encouraged?" "forced?" "asked?")
The author sees the following problems with this hypothesis:
- Origin - do-periphrasis originated in the Western dialects, but those were the one that used causative do the least.
- Motivation - it's harder to claim that an optional causative "do", with no independent semantic value, would eventually evolve into the do-support currently used.
Other hypotheses addressed were the usage of 'do' as a perfective aspect marker and verbal ellipsis. And then the author actually addresses the hypothesis he believes to be correct, linking current do-support to the habitual aspect; for example, in the sentence "I do browse Lemmy", that "do" can be understood as both an emphasiser and as conveying "by rule, usually".
![know one's \[general subject of interest\]](https://media.kbin.social/media/c6/89/c6898656a4b020f7a37658e7c88ec1a6af87f3041470dc4c21db813d635a0717.webp){kind=link}