Aotearoa Daily Kōrero 25/3/2024
Aotearoa Daily Kōrero 25/3/2024
Welcome to today’s daily kōrero!
Anyone can make the thread, first in first served. If you are here on a day and there’s no daily thread, feel free to create it!
Anyway, it’s just a chance to talk about your day, what you have planned, what you have done, etc.
So, how’s it going?
You're viewing a single thread.
So I'm still not feeling great, but getting a bit more energy now. Spent the weekend doing not much. Must have had whatever @[email protected] and @[email protected] had 🙁
On the plus side, we are looking a lot healthier on the federation front with Lemmy.world. It seems we can't make much progress with weekday traffic but when the weekend comes there's a lot less content and so we can catch up some more. We are currently down to about 2 hours delay for content coming from Lemmy.world to Lemmy.nz. Here's a graph:
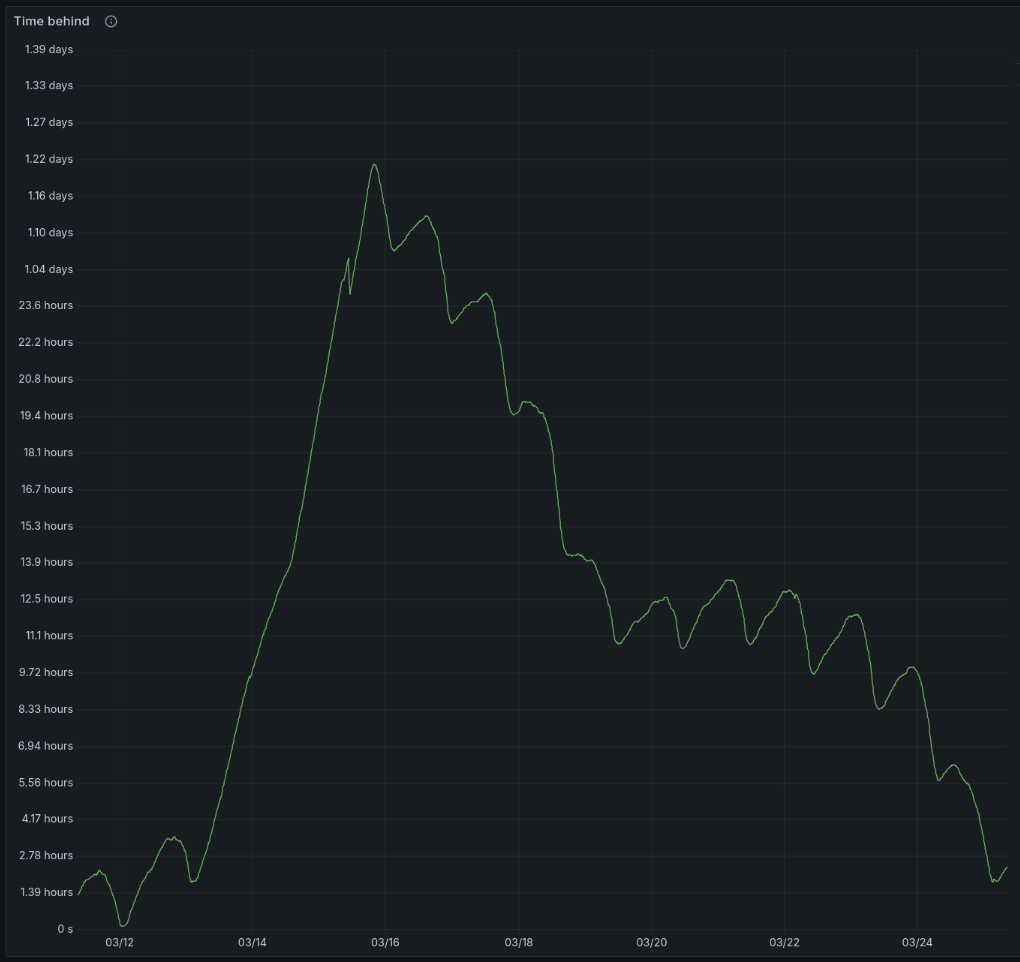
And here's one showing the number of "activities" (actions) behind we are:
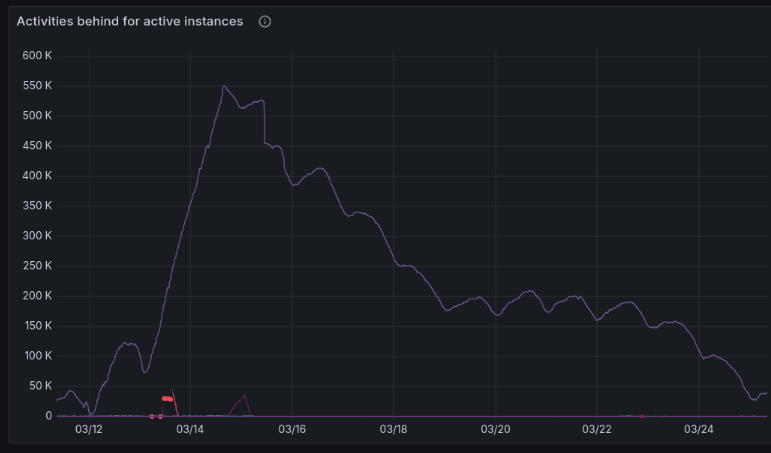
Sorry for having one graph weirdly thin and tall, they are on the same timeline, but they seem to display different. I didn't make the graphs, but they are publicly accessible here and here.
These are pretty neat graphs! Is it sourced from the Prometheus logs?
Just updated to 0.19.3 but the DB migrations failed due to a permissions change I made a while back to my DB, so I had to spend a few hours in the SQL dungeons fixing things.
I didn't make the dashboards, but the data is available through an API call to each instance. I guess they have some polling set up and then feed it into the dashboard?
I've been testing some stuff with pictrs, and have been updating pictrs from 0.4 to 0.5 in my non-prod instance. There's no progress meter and so far it has taken 2 days 😱.
It's a lot less grunty than the production server but still seems excessive!
Interesting. I have some New Relic stuff setup with my cluster but most of that is just resource usage stuff. I ran out of RAM a while back so I've had to be a bit more restrictive about how many connections Lemmy can have to postgres db.
There’s no progress meter and so far it has taken 2 days 😱.
Uh oh. I considered updating to 0.5 as part of my 0.18.3-ish (I was running a custom fork I made with some image caching stuff that has since been merged in to real lemmy) -> 0.19.3 upgrade but I'm glad I didn't.
Thanks for the heads up. Are you migrating to postgres for pictrs too, or sticking with sled?
I ran out of RAM a while back so I’ve had to be a bit more restrictive about how many connections Lemmy can have to postgres db.
I just have a cronjob to restart the backend lemmy container every night 😆
Thanks for the heads up. Are you migrating to postgres for pictrs too, or sticking with sled?
My plan is to go to postgres but this migration is just for sled. I was doing it for another reason, to test out a cache cleaning setup. Currently the pictrs image cache is 250-300gb because it's never deleted anything (because lemmy doesn't do that).
Lemmy.world said it took them 4 hours, and they have a grunty machine. Not sure what their cache looked like, though. I think they were also moving to postgres.
cronjob to restart the backend lemmy container
Fair enough, that'd work. I run my database in a different pod to lemmy (I run this all in kubernetes), and I cannot restart that pod without causing an outage for a bunch of other things like my personal website. I ended up just needing to tune my config to have a maximum RAM usage and then configuring k8s to request that much RAM for the DB pod, so it always has the resources it needs.
pictrs image cache is 250-300gb
oof :(
That's what my custom lemmy patch was, it turned off pictrs caching. That's now in lemmy as a config flag (currently a boolean but in 0.20 it will be on/off/proxy where the proxy option goes via your pictrs but does not cache). I then went back through mine and did a bunch of SQL to figure out which pictrs images I could safely delete and got my cache down to 3GB.I'm not using kubernetes and know nothing about it, but I don't need to restart postgres, only the 'lemmy' container that runs the lemmy backend. By doing this the connections are all severed, the RAM is freed up, and it's all good again. I should probably learn how to limit connections in another way!
Instead of doing all the working out about pictrs images, I'm just looking at using this: https://github.com/wereii/lemmy-thumbnail-cleaner
An added benefit being that it stays running and keeps your cache trimmed to the timeframe you state. I'm happy with a cache but after a week it's not really that helpful. Unfortunately the endpoint in pictrs that deletes the image and removed from the db that this script uses is not in pictrs 0.4.x so I thought I'd quickly run the upgrade in non-prod and test it out. It's still running, I started it about lunchtime on Saturday! I'm seriously considering pulling the plug and doing it properly into postgres, but it would be nice to know how long it's gonna take, so I'm also tempted to leave it running. It's running on an old Vaio laptop set up as a server. I think this machine is older than I first thought, perhaps from 2012, so that might explain a lot!
By doing this the connections are all severed, the RAM is freed up, and it’s all good again.
Ah, neat! I didn't think of that. You can limit the size of the connection pool in your lemmy config fwiw.
Nice, that looks like it's doing a similar thing to my weird mess of SQL and Python that I did last year haha
Good luck for the migration :)
Ah, neat! I didn’t think of that. You can limit the size of the connection pool in your lemmy config fwiw.
Mine's set to 10 and it was using up 32GB of RAM so I suspect something wasn't working right there 😆
Nice, that looks like it’s doing a similar thing to my weird mess of SQL and Python that I did last year haha
A couple of days back one of the lemmy devs posted a quick example bash script in one of the instance admin matrix chats. It didn't quite work, but someone else was inspired to write their own system and posted the code on github. So feel better knowing someone else hadn't already done the work for you at the time you were doing it 🙂