Selenium Web Browser Automation
-
How do I get rid of this annoying Popup (without having to remove Teams from my machine)
It doesn't let me proceed or click any other button without manually closing the popup which I cannot do when I run the script with the headless argument. Any help would be much appreciated!
-
Selenium on Outlook Web
I have automated tests that until the 27th of August worked flawlessly. my testcase goes to outlook web and confirms the receipt of an email. I am now stumbling over the login process. I am able to find the loginbutton but my selenium code fails to find the input fields.
i tried modifying the selection strategy but that made no difference.
I ran some basic javascript queries in the dev console but as best as i can tell the input field is visible, clickable and on top.
Does anybody have any idea what might be the issue?
-
Has anyone used Alchemy to generate Selenium Code?
It looks like a cool web testing tool that generates Selenium Code. However, it is fairly new. I am looking for real user feedback. Thanks
-
How to create docker file with Chrome browser and chrome driver dependencies for a Java based Selenium application
This is related to a maven 3.9.6-based and java 17-based selenium automation project used to log and download files from a remote site, it works fine as a nonotorized application.
This application uses the Chrome browser in headless mode. Currently, the Chrome drivers and relevant Maven versions are bundled with it in the application. The Chrome drivers have to match the Chrome browser for the Selenium operations to work without error. The Chrome browser version in the current server is 123.0.6312.86 and the drivers in drivers/chromedriver-linux64 are used. The Chrome drivers need to be updated if the Chrome browser is updated on the server. I have placed the report-automation.jar at the root level of the application during the build.
Currently, the Chrome browser should be installed on a server and is not bundled into the application in any way. The related Chrome drivers are only bundled in the application. how can this application be dockerized? should the Chrome browser and Chrome driver installation be handled in the docker file?
Given below is a sample docker file I created for this scenario. But the Chrome browser and Chrome driver-related sections need to be updated Could the docker file be optimized further to support containerization optimally?
Furthermore, the outcome of this application is to download a CSV report Downloaded-Report folder in the application. How can this operation be handled if the application is dockerized?
[`OS Version/build - Ubuntu 18.04 LTS Docker Version - 24.0.2, build cb74dfc Maven Version - 3.9.6 Java Version - 17.04 Chrome browser version - 123.0.6312.86`]()The currently used docker file is given below:
``` [`# Use the official OpenJDK 17 image as a base image FROM maven:3.9.6-eclipse-temurin-17-alpine AS builder
Set the working directory inside the container
WORKDIR /app RUN chmod -R 777 /app
Install tools.
RUN apk update && apk add --no-cache wget unzip
[#######################
Install Chrome.
Adding Google Chrome repository
RUN apk add --no-cache --repository=http://dl-cdn.alpinelinux.org/alpine/edge/community google-chrome-stable
#######################
Download the Chrome Driver
RUN wget -O /tmp/chromedriver.zip http://chromedriver.storage.googleapis.com/$(wget -qO- https://chromedriver.storage.googleapis.com/LATEST_RELEASE)/chromedriver_linux64.zip \ && unzip /tmp/chromedriver.zip -d /usr/local/bin/ \ && rm /tmp/chromedriver.zip ENV PATH="/usr/local/bin:${PATH}" #######################
Copy the entire project (assuming Dockerfile is in the project root)
COPY . .
Build the application using Maven
RUN mvn package -DskipTests
Use the official OpenJDK 17 image as the final image
FROM eclipse-temurin:17.0.6_10-jdk@sha256:13817c2faa739c0351f97efabed0582a26e9e6745a6fb9c47d17f4365e56327d
Set the working directory inside the container
WORKDIR /app
Copy the JAR file and other necessary files to the container
COPY --from=builder /app/report-automation.jar /app/report-automation.jar COPY --from=builder /app/src/main/resources/META-INF/MANIFEST.MF /app/META-INF/MANIFEST.MF COPY --from=builder /app/src/main/resources/config.properties /app/config.properties COPY --from=builder /app/pom.xml /app/pom.xml COPY --from=builder /app/testng.xml /app/testng.xml COPY --from=builder /app/application.properties /app/application.properties COPY --from=builder /app/Configuration.xlsm /app/Configuration.xlsm COPY --from=builder /app/apache-maven-3.9.6/ /app/apache-maven-3.9.6/ COPY --from=builder /app/Downloads /app/Downloads COPY --from=builder /app/Downloaded-Report /app/Downloaded-Report COPY --from=builder /app/Logs /app/Logs COPY --from=builder /app/Reports /app/Reports COPY --from=builder /app/drivers /app/drivers
Expose the port (if your application listens on a specific port)
EXPOSE 8080
Set the entry point for the container
ENTRYPOINT ["java", "-Xmx512m", "-Xms256m", "-jar", "report-automation.jar"]`]]() ```
The application's hierarchical structure is mentioned below.
```
/workspace/report-automation$ tree -L 2 . ├── apache-maven-3.9.6 //Bundled maven │ ├── application.properties ├ ├── Configuration.xlsm ├── Dockerfile ├── Downloaded-Report │ └── SalesReport.csv //Downloaded report ├── Downloads ├── drivers │ ├── chromedriver-linux64 //Bundled chrome drivers │ └── chromedriver-mac-arm64 ├── Logs │ └── TestLogs.log ├── out │ └── artifacts ├── pom.xml ├── README.md ├── report-automation.jar // Applications jar file ├── Reports │ └── ExtentReport.html ├── src │ └── main ├── target │ ├── classes │ ├── generated-sources │ ├── maven-archiver │ ├── maven-status │ ├── surefire-reports │ └── testng.xml``` This error is also thrown when the docker file is being built.
``` `randunu@randunu:/rezsystem/workspace/report-automation$ sudo docker build -t report-automation .
[+] Building 358.0s (9/27) => [internal] load build definition from Dockerfile 0.0s => => transferring dockerfile: 2.48kB 0.0s => [internal] load .dockerignore 0.0s => => transferring context: 2B 0.0s => [internal] load metadata for docker.io/library/eclipse-temurin:17.0.6_10-jdk@sha256:13817c2faa739c0351f97efabed0582a26e9e6745a6fb9c47d17f4365e56327d 0.0s => [internal] load metadata for docker.io/library/maven:3.9.6-eclipse-temurin-17 3.0s => [internal] load build context 0.1s => => transferring context: 51.39kB 0.0s => CANCELED [builder 1/4] FROM docker.io/library/maven:3.9.6-eclipse-temurin-17@sha256:29a1658b1f3078e07c2b17f7b519b45eb47f65d9628e887eac45a8c5c8f939d4 354.9s => => resolve docker.io/library/maven:3.9.6-eclipse-temurin-17@sha256:29a1658b1f3078e07c2b17f7b519b45eb47f65d9628e887eac45a8c5c8f939d4 0.0s => => sha256:408d89a73e0dc1b14cfbc003f5729720855da4003a266ebf841cf2c298a8d144 2.41kB / 2.41kB 0.0s => => sha256:5e5d1bccc5440d3a24f4a620704b9e687b4163c6c872fcc8e812e200c9bbac58 17.46MB / 17.46MB 120.0s => => sha256:29a1658b1f3078e07c2b17f7b519b45eb47f65d9628e887eac45a8c5c8f939d4 1.21kB / 1.21kB 0.0s => => sha256:b86805e902bf7f1eb3cd9d7f99f0cb391aacca9fe5653ba2c8279d2f0a4e2c23 7.91kB / 7.91kB 0.0s => => sha256:4a023cab5400feb5c1ab725beb8345ddb0e3200314004b56677a5eee2e8c86cf 30.44MB / 30.44MB 236.3s => => sha256:d59fd278c1b4ffe1727be6ccba42125e8f4db57e660e795cce19889d2c776457 61.87MB / 145.10MB 354.9s => => sha256:c97285723537ab7921fca4d081c256e501adfdaa8992d04637992075f4cea392 173B / 173B 122.1s => => sha256:a3ba11f7aaaedad962216812fe84aee9061aeabac6932f0274a1d204eb96e8e8 734B / 734B 122.5s => => sha256:67f99c2668af1d0eced6d61dad057d7beffe543a8e8370d5c0d3fe8682e059a3 19.00MB / 19.00MB 275.5s => => sha256:45f480637770dbb740623c0c7f827d44bbacc9204faf3d07b4135d54a2bee043 9.48MB / 9.48MB 293.0s => => extracting sha256:4a023cab5400feb5c1ab725beb8345ddb0e3200314004b56677a5eee2e8c86cf 0.5s => => extracting sha256:5e5d1bccc5440d3a24f4a620704b9e687b4163c6c872fcc8e812e200c9bbac58 0.4s => => sha256:58c3491a14ebc973960cbda9f2eea22537785a3cb07e81487bd1115bad4a8278 852B / 852B 276.5s => => sha256:4712dfa85971124b8c3507fbba4c02441e5754f1517162926e600afd3fc5404b 358B / 358B 276.9s => => sha256:fc06d68d71ba375a9ceed165c0c04b09b1a8cc193146888663b005660fc25013 156B / 156B 277.4s => [stage-1 1/18] FROM docker.io/library/eclipse-temurin:17.0.6_10-jdk@sha256:13817c2faa739c0351f97efabed0582a26e9e6745a6fb9c47d17f4365e56327d 0.0s => CACHED [stage-1 2/18] WORKDIR /app 0.0s => ERROR [stage-1 3/18] RUN apt-get update && apt-get install -y wget unzip gnupg && wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.p 354.9s ------ > [stage-1 3/18] RUN apt-get update && apt-get install -y wget unzip gnupg && wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add - && sh -c 'echo "deb http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google-chrome.list' && apt-get update && apt-get install -y google-chrome-stable && apt-get clean && rm -rf /var/lib/apt/lists/: #0 1.293 Get:1 http://archive.ubuntu.com/ubuntu jammy InRelease [270 kB] #0 3.757 Get:2 http://security.ubuntu.com/ubuntu jammy-security InRelease [129 kB] #0 6.756 Get:3 http://security.ubuntu.com/ubuntu jammy-security/multiverse amd64 Packages [44.7 kB] #0 7.154 Get:4 http://archive.ubuntu.com/ubuntu jammy-updates InRelease [128 kB] #0 7.157 Get:5 http://security.ubuntu.com/ubuntu jammy-security/main amd64 Packages [2,118 kB] #0 10.38 Get:6 http://archive.ubuntu.com/ubuntu jammy-backports InRelease [127 kB] #0 13.30 Get:7 http://archive.ubuntu.com/ubuntu jammy/main amd64 Packages [1,792 kB] #0 25.08 Get:8 http://security.ubuntu.com/ubuntu jammy-security/universe amd64 Packages [1,131 kB] #0 34.61 Get:9 http://security.ubuntu.com/ubuntu jammy-security/restricted amd64 Packages [2,787 kB] #0 53.25 Get:10 http://archive.ubuntu.com/ubuntu jammy/multiverse amd64 Packages [266 kB] #0 60.66 Get:11 http://archive.ubuntu.com/ubuntu jammy/restricted amd64 Packages [164 kB] #0 65.24 Get:12 http://archive.ubuntu.com/ubuntu jammy/universe amd64 Packages [17.5 MB] #0 300.8 Get:13 http://archive.ubuntu.com/ubuntu jammy-updates/multiverse amd64 Packages [51.8 kB] #0 301.5 Get:14 http://archive.ubuntu.com/ubuntu jammy-updates/main amd64 Packages [2,396 kB] #0 323.5 Get:15 http://archive.ubuntu.com/ubuntu jammy-updates/universe amd64 Packages [1,421 kB] #0 332.4 Get:16 http://archive.ubuntu.com/ubuntu jammy-updates/restricted amd64 Packages [2,884 kB] #0 352.6 Get:17 http://archive.ubuntu.com/ubuntu jammy-backports/universe amd64 Packages [33.7 kB] #0 353.4 Get:18 http://archive.ubuntu.com/ubuntu jammy-backports/main amd64 Packages [81.0 kB] #0 354.0 Fetched 33.3 MB in 5min 54s (94.2 kB/s) #0 354.0 Reading package lists... #0 354.8 E: Problem executing scripts APT::Update::Post-Invoke 'rm -f /var/cache/apt/archives/.deb /var/cache/apt/archives/partial/.deb /var/cache/apt/.bin || true' #0 354.8 E: Sub-process returned an error code ------ ERROR: failed to solve: executor failed running [/bin/sh -c apt-get update && apt-get install -y wget unzip gnupg && wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add - && sh -c 'echo "deb http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google-chrome.list' && apt-get update && apt-get install -y google-chrome-stable && apt-get clean && rm -rf /var/lib/apt/lists/*]: exit code: 100` ```
any suggestions on how this issue may be handled?
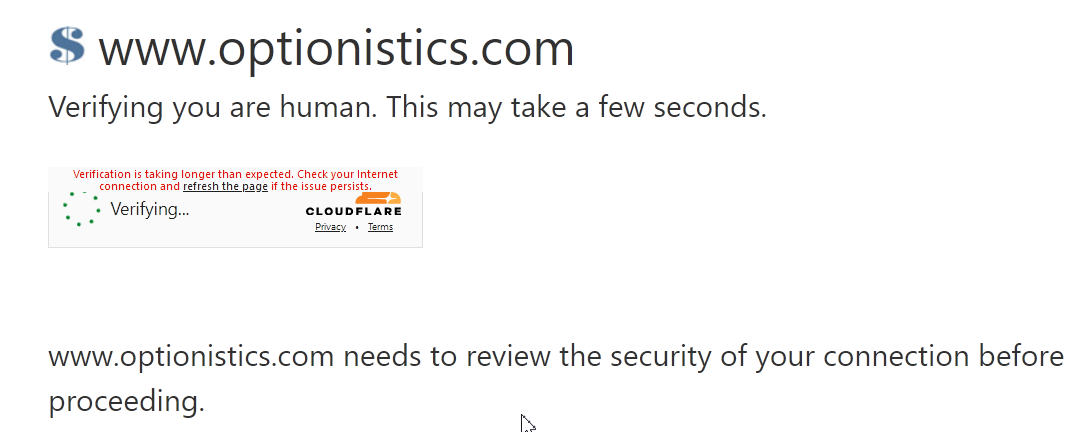
- stackoverflow.com I'm a human, But I can't pass the human check in the broswer of selenium
I'm using selenium to open the webpage https://www.optionistics.com/quotes/stock-option-chains/GOOG It was loaded successfully at first. from selenium import webdriver from selenium.webdriver.commo...

I'm using selenium to open the webpage https://www.optionistics.com/quotes/stock-option-chains/GOOG It was loaded successfully at first. ```
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait, Select from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.firefox.service import Service as FirefoxService from webdriver_manager.firefox import GeckoDriverManager from selenium.webdriver.firefox.options import Options
options = Options() options.set_preference("general.useragent.override", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36") driver = webdriver.Firefox(service=FirefoxService(GeckoDriverManager().install()),options=options) driver.get("https://www.optionistics.com/quotes/stock-option-chains/GOOG")
``` And then I came across the human verification after I changed the settings in the web page (for example, the "report date") and the form submitted to fetch new data. The problem is, I can't pass the check myself by clicking checkbox. After click, it would pend for a while before refreshd and showed the checkbox again. I clicked and it won't let me through
I'm not meant to bypass it. I just want to get myself verified. Is the Cloudflare expecting something from the header?
-
Trying to Automate Website Survey
Noob--I'm trying to automate verification of survey completion for 600 users. I can open the page fine, but struggle putting a value into the input box. What am I missing? Any help appreciated.
Website: https://gptw.care/vi
Input: document.querySelector("#root > div > div.MuiFormControl-root.MuiTextField-root.jss16")
``` #SingleInstance, force #Include, Lib\Chrome\Chrome.ahk ;https://github.com/G33kDude/Chrome.ahk/releases
; verify if the profile folder exists ; if not, create it if !FileExist("profile") FileCreateDir, % "profile"
; load the chrome object pointing to the folder created above ; and the link to the page (or pages) to open at startup chrome := new chrome("profile", "https://gptw.care/vi")
; get the first page (you can use other functions to select a specific page, like GetPageByTitle() or GetPageByURL()) pg := chrome.getpage()
; wait for the page to finish loading before clicking anything. ; clicking on an nonexistant element results in an error pg.WaitForLoad("complete")
; pass arbitrary javascript to the page. This allows you to do virtually anything you want ; with the page pg.Evaluate("document.querySelector('#root > div > div.MuiFormControl-root.MuiTextField-root.jss16').value = '7654321'")
return ```
-
problem with python 3.11 + selenium + telegram
Hi! I have developed an application for parsing store products with uploading product cards to telegram. And it works, but only on a local computer. When the application is uploaded to the hosting, the program doesn't show any errors, but the product cards don't appear. Please help me. main.py ``` from selenium import webdriver from selenium.webdriver.chrome.service import Service from congif import * def ex(func): async def show_ex(*args, **kwargs): try: await func(*args, **kwargs) except Exception as e: print('Error: ', e) return show_ex @ex async def create_table(cursor, word): try: await cursor.execute(f''' CREATE TABLE IF NOT EXISTS {word.lower()} ( id INTEGER PRIMARY KEY AUTOINCREMENT, price TEXT, link TEXT UNIQUE, img TEXT ) ''') except sqlite3.OperationalError: time.sleep(10) await cursor.execute(f''' CREATE TABLE IF NOT EXISTS {word.lower()} ( id INTEGER PRIMARY KEY AUTOINCREMENT, price TEXT, link TEXT UNIQUE, img TEXT ) ''') @ex async def insert_data(cursor, word, new_price, link, img): try: await cursor.execute(f''' INSERT INTO {word.replace(" ", "").lower()} (price, link, img) VALUES (?, ?, ?) ''', (new_price, link, img)) except sqlite3.IntegrityError: pass except sqlite3.OperationalError: time.sleep(10) await cursor.execute(f''' INSERT INTO {word.replace(" ", "").lower()} (price, link, img) VALUES (?, ?, ?) ''', (new_price, link, img)) @ex async def check_table_exists(conn, table_name): async with conn.cursor() as cursor: await cursor.execute(f"SELECT name FROM sqlite_master WHERE type='table' AND name='{table_name.lower()}';") return await cursor.fetchone() is not None @ex async def send_product_messages(user_id, card, img_url): try: await bot.send_photo(user_id, photo=img_url, caption=card) except Exception as e: print(f"Error: {e}") @ex async def process_user(user_id, products): conn = await aiosqlite.connect('/data/mercaridata.db') async with conn.cursor() as cursor: tasks = [] for product_key, product_value in products.items(): table_exists = await check_table_exists(conn, product_value) if not table_exists: await create_table(cursor, product_value.replace(" ", '')) url = f'https://jp.mercari.com/search?keyword={product_value.replace(" ", "%20")}&sort=created_time&order=desc' task = asyncio.create_task(process_product(user_id, cursor, product_value, url)) tasks.append(task) await asyncio.gather(*tasks) await conn.commit() @ex async def process_product(user_id, cursor, product_value, url): options = webdriver.ChromeOptions() options.add_argument("--headless") options.add_argument("--no-sandbox") options.add_argument("--disable-gpu") options.add_argument("--remote-debugging-port=9230") driver = webdriver.Chrome(options=options) try: driver.maximize_window() driver.get(url) card_divs = driver.find_elements(By.XPATH, '//li[@class="sc-bcd1c877-2 gWHcGv"]')[:10] for card_div in card_divs: try: price = float( (card_div.find_element(By.TAG_NAME, 'span').text.replace(' ', '').replace(',', ''). replace('\n', ''))) except ValueError: price = 'SALE!' except Exception: price = '?' try: link = card_div.find_element(By.TAG_NAME, 'a').get_attribute('href') except Exception: continue img = card_div.find_element(By.TAG_NAME, 'img').get_attribute('src') await insert_data(cursor, product_value, price, link, img) print(price, link, img) card = (f"Item: {link} \n" f"Price: {price} $.\n") if card: await send_product_messages(user_id, card, img) else: print('ТNo items') await bot.send_message(user_id, 'No items') finally: driver.stop_client() driver.close() driver.quit()
```
-
Disable error message from attempting to check geckodriver for updates
So I sometimes run selenium without being connected to the internet, and whenever I do that it spits out this error message:
Exception managing firefox: error sending request for url (https://github.com/mozilla/geckodriver/releases/latest): error trying to connect: dns error: No such host is known. (os error 11001)Now of course I could wrap it in a try-catch-statement, but is there a proper way to prevent displaying this message (or disable the update check)? The code still works properly, I just don't wanna see the message, or even control the update check.
-
Selenium Manager can't download through proxy
I'm behind a company proxy and am normally able to do anything if I just point to it(no user/pass required). I've tried about all the different options to set it, the last one was the example of the docs here: https://www.selenium.dev/documentation/webdriver/drivers/options/#proxy
But every time there's a Geckodriver update I run into the same NoSuchDriverException: Message: Unable to obtain geckodriver using Selenium Manager: Message: Unsuccessful command executed. Error sending request for url (https://github.com/mozilla/geckodiver/releases/latest): error trying to connect: tcp connect error: something something os error 10060.
Does setting the webdriver desiredcapabilities proxy even have an effect on the selenium manager that downloads the new driver?
-
Trying to download a file
I'm trying to automate a process where I log into a website, download a series of documents, process them, then re-upload. I'm having trouble downloading; the preferences don't seem to work:
chromedriver_path = "C:\\Users\\XXX\\PycharmProjects\\YYY\\util_files\\chromedriver-win64\\chromedriver.exe" service = Service(chromedriver_path) options = Options() options.headless = True options.add_argument("--incognito") prefs = {"download.default_directory": "C:\\Users\\XXX\\Downloads", "download.prompt_for_download": False, "download.directory_upgrade": True} options.add_experimental_option("prefs", prefs) driver = webdriver.Chrome(service=service, options=options)It doesn't run it headless (not a big deal) but it keeps prompting me with the download dialog. It's tough to find a solution online because it seems like Selenium has updated how it does some things over time, so I don't know of my code is the most up to date or not. TIA -
how to handle chrome profile selection pop-up when launching the browser
I can't get selenium (on Python 3.11) to interact with the chrome's (122.0.6261.112 (Official Build) (64-bit) (cohort: Stable)) profile selection pop-up (on the browser start-up) correctly.
So far I've tried:
- finding elements by visible text (nothing is found when searching for an XPATH containing "Sign in")
- keyboard navigation (TAB switches between elements but ENTER doesn't open the login pop-up despite playing the 'click animation')
- moving the cursor to the element I got the TAB to highlight and clicking (click() action de-selects the highlighted element)
- disabling the profile selection window by parsing options arguments when launching the browser (best I got was no default profile listed on the pop-up)
- logging-in manually for the duration of the test session (chrome opens new window which messes up the 'yield' statement of my browser fixture because "window is already closed, duh"; that login doesn't persist between browser sessions so the pop-up appears again)
I'm bound to testing with the stable chrome because of the company policy. Our IT is controlling the versioning and might even force certain policies on the browser behavior. This profile selector started showing up yesterday and I really need to either disable it or get past it.
-
Videos load in local selenium test, but not on ec2 server?
Hello, I'm attempting to screenshot tweets with selenium and some other python packages. I have it working perfectly in my local environment, but when i attempt to run the script via my ec2 instance, videos within tweets are unable to load. iIve tried adding the enable-javascript arg, which doesn't help.
has anyone encountered this issue? using python 3.11.5 with selenium 4.16, latest stable chromedriver, and im on an amazon ec2 server running the script with gunicorn.. using the following args:
chrome_options.add_argument("--headless") chrome_options.add_argument("--no-sandbox") chrome_options.add_argument("--disable-gpu") chrome_options.add_argument("--test-type") chrome_options.add_argument("--disable-logging") chrome_options.add_argument('--ignore-certificate-errors') chrome_options.add_argument("--disable-dev-shm-usage") chrome_options.add_argument(f"--window-size={ceil(1024*scale)},{ceil(1024*scale)}") chrome_options.add_argument("--remote-debugging-port=9222") chrome_options.add_argument("--incognito") chrome_options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36")any help is much appreciated.
-
Selenium WebDriver Fails to Locate Elements on Linux Server but works locally
I'm experiencing an issue with my web scraper running on a Linux server where it fails to locate elements using Selenium WebDriver. The scraper works perfectly fine on my local machine, but when I run it on the Linux server, it throws a NoSuchElementException.
The error message I receive is:
>selenium.common.exceptions.NoSuchElementException: Message: no such element: Unable to locate element: {"method":"css selector","selector":".Crom_table__p1iZz"}
I've tried using WebDriverWait to wait for the table to load, but it doesn't seem to be working. Additionally, I've logged the page source on the Linux server and compared it to my local machine, and I've noticed significant differences in the HTML structure.
I am using a custom user-agent to prevent differences, but that hasn't resolved the issue. I'm not sure what else to try to resolve this issue.
Here's a snippet of my code:
``` def team_defenses(season): url = 'https://www.nba.com/stats/teams/defense?Season=' + season
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=get_driver_options())
driver.get(url)
# Wait for the table to load, if it doesn't load display content try: WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CLASS_NAME, 'Crom_table__p1iZz'))) except Exception as e: print(f"Error: {e}") with open('error_page_source.txt', 'w') as f: f.write(driver.page_source) driver.quit() return
table = driver.find_element(By.CLASS_NAME, 'Crom_table__p1iZz')
# ... rest of my code ...
driver.quit()
def get_driver_options(): options = Options() options.add_argument('--headless') # Runs Chrome in headless mode. options.add_argument('--no-sandbox') # Bypass OS security model options.add_argument('--disable-dev-shm-usage') # Overcome limited resource problems return options
-
detecting page change
I wrote a script to brute force a solution to a quiz on a google forms page There is a text field and a button Entering a guess in the field and pressing the button results in either a text message that the solution is wrong or a new page is loaded saying the answer is correct
I successfully wrote a simple loop that changes the text of the field and presses the button
- How can I detect the page change after the button is pressed? (when the guess is correct)
- When I just looped through the numbers 000-999 the solution page did not load (I was expecting the script to fail at the next number since the input field is not present in the solution page). However, when I debugged the script, single-stepping the solution caused the browser to load the solution page. Do I need to add a delay (sleep) after the button click?
-
Having an issue running the Selenium application inside the docker
To run the Java Selenium application on a separate server I am attempting to build a Dockerfile install Chrome and use a headless way to run a browser. (This application provides a desired output when executed locally.) But when attempting to run the docker I receive this error.
Am I missing something in the docker build or the Java-based configurations provided.? How should chrome driver-related configurations be added?
Technologies used
- OS - Ubuntu 22.04 LTS
- Docker version - Docker version 24.0.2, build cb74dfc
- Java version - java version "17.0.4" 2022-07-19 LTS
- Selenium version - 4.11.0
- Chrome version - Google Chrome 120.0.6099.199--
Update: There also seems to be another way to run Chrome using selenium/standalone-chrome. Is it possible to integrate chrome/selenium with another docker using this method? which is the preferred option of these two methods?
``` >FAILED CONFIGURATION: u/BeforeClass openBrowser
org.openqa.selenium.remote.NoSuchDriverException: Unable to obtain: Capabilities {browserName: chrome, goog:chromeOptions: {args: [--remote-allow-origins=*, --headless], extensions: [], prefs: {download.default_directory: report/}}}, error Command failed with code: 65, executed: [/tmp/selenium-manager246697546082813077936780283589629/selenium-manager, --browser, chrome, --output, json]
request or response body error: operation timed out
Build info: version: '4.11.0', revision: '040bc5406b' System info: os.name: 'Linux', os.arch: 'amd64', os.version: '5.4.0-150-generic', java.version: '17.0.6'
Driver info: driver.version: ChromeDriver at org.openqa.selenium.remote.service.DriverFinder.getPath(DriverFinder.java:25) at org.openqa.selenium.remote.service.DriverFinder.getPath(DriverFinder.java:13) at org.openqa.selenium.chrome.ChromeDriver.generateExecutor(ChromeDriver.java:99) at org.openqa.selenium.chrome.ChromeDriver.(ChromeDriver.java:88) at org.openqa.selenium.chrome.ChromeDriver.(ChromeDriver.java:83) at org.openqa.selenium.chrome.ChromeDriver.(ChromeDriver.java:72) at Infra.BasePage.openBrowser(BasePage.java:108) ``` Caused by: org.openqa.selenium.WebDriverException: Command failed with code: 65, executed: [/tmp/selenium-manager246697546082813077936780283589629/selenium-manager, --browser, chrome, --output, json]
request or response body error: operation timed out Build info: version: '4.11.0', revision: '040bc5406b' System info: os.name: 'Linux', os.arch: 'amd64', os.version: '5.4.0-150-generic', java.version: '17.0.6' Driver info: driver.version: ChromeDriver at org.openqa.selenium.manager.SeleniumManager.runCommand(SeleniumManager.java:151) at org.openqa.selenium.manager.SeleniumManager.getDriverPath(SeleniumManager.java:273) at org.openqa.selenium.remote.service.DriverFinder.getPath(DriverFinder.java:22)
-
How do you start Selenium+Firefox on Linux using a custom Geckodriver and Firefox path?
``` from selenium import webdriver from selenium.webdriver.firefox.service import Service from selenium.webdriver.firefox.options import Options
options = Options() options.binary_location = '/mnt/sdb1/firefox/'
driver = webdriver.Firefox(options = options, service=Service(executable_path = '/mnt/sdb1/root'))
driver.get('https://youtube.com') driver.execute_script('alert(\'your favorite music is here\')') ``` I get the following error
Traceback (most recent call last): File "/mnt/sdb1/root/sele.py", line 8, in driver = webdriver.Firefox(options = options, service=Service(executable_path = '/mnt/sdb1/root')) File "/usr/local/lib/python3.9/dist-packages/selenium/webdriver/firefox/webdriver.py", line 59, in __init__ self.service.path = DriverFinder.get_path(self.service, options) File "/usr/local/lib/python3.9/dist-packages/selenium/webdriver/common/driver_finder.py", line 44, in get_path raise NoSuchDriverException(f"Unable to locate or obtain driver for {options.capabilities['browserName']}") selenium.common.exceptions.NoSuchDriverException: Message: Unable to locate or obtain driver for firefox; For documentation on this error, please visit: https://www.selenium.dev/documentation/webdriver/troubleshooting/errors/driver_location -
Testing Library locators for Selenium (Java/Kotlin)
github.com GitHub - lsoares/selenium-testing-library: Selenium locators for Java/Kotlin that resemble the Testing Library (testing-library.com).Selenium locators for Java/Kotlin that resemble the Testing Library (testing-library.com). - GitHub - lsoares/selenium-testing-library: Selenium locators for Java/Kotlin that resemble the Testing L...

I've created a library to bring the Testing Library (testing-library.com) to Selenium (Kotlin/Java) since it's an awesome library with great principles for promoting usability, accessibility, and tests that don't depend on tech details. Check it out!
>The more your tests resemble the way your software is used, the more confidence they can give you. (Kent C. Dodds)
-
need help automating marketplace
Hi, so I post around 30 facebook market place ads a month, its a super tideious task and could easily be done by a computer. The issue is, is that facebook has such a weird structure when I inspect elements. the image attached is a example of it, the class names are this weird code, and I cant find any names, ids, on these elements to give to Selenium. at the moment I use py auto GUI + selenium to click around the web page, but this is super hard coded and doesn't work all the time. so please let me know what you guys recommend
-
I keep getting certificate errors when using Selenium.
So I am a brand new user of Selenium in Python. I am really enthusiastic about using this framework, but I'm encountering some issues with certificate errors. When I Google for this issue, I noticed several users in the past year having similar issues but nobody really providing a workable solution.
I'm essentially testing out Selenium by trying out the first script in the documentation before cutting my teeth on scraping my actual target website which I plan to do after everything is smooth with the first script that acts as my baseline to ensure that everything in my development environment is setup right:
https://www.selenium.dev/documentation/webdriver/getting_started/first_script/
Note that the official documentation never actually tells me to install the Selenium web driver. It just tells me to install Selenium on my Python virtual environment which I did using "pip install selenium".
However at the time of reviewing the above documentation I was aware that a separate web driver for the web browser of choice was needed too. In my case I use Chrome. I decided I would first just follow the official documentation and see what would happen.
I pasted in the code verbatim from the Selenium github (https://github.com/SeleniumHQ/seleniumhq.github.io/blob/trunk/examples/python/tests/getting_started/first_script.py#L4) into first_script.py and then ran it in my python interpreter.
To my surprise it did spawn a browser briefly and then closed. But it's throwing up several certificate errors:
[2944:20700:1219/211513.232:ERROR:cert_issuer_source_aia.cc(34)] Error parsing cert retrieved from AIA (as DER): ERROR: Couldn't read tbsCertificate as SEQUENCE ERROR: Failed parsing CertificateUpon further inspection the script does appear to submit the form and then scrape the form results page as it correctly scripts "Received!" and stores it as a string in the "text" variable.
However the certificate errors are a huge problem I need resolved. My normal Chrome installation doesn't throw up any certificate errors on https://www.selenium.dev/selenium/web/web-form.html which the above Selenium script submits and then scrapes the result. The web form url has a perfectly valid lets encrypt SSL certificate.
Remember I mentioned that I didn't install the web driver since it wasn't mentioned in the official document? I decided to rectify that since I figured maybe that could be the problem.
Since I am using Chrome 120.0.6099.110 I went to https://sites.google.com/chromium.org/driver/downloads?authuser=0 which instructed me to go here: https://googlechromelabs.github.io/chrome-for-testing/
I grabbed chromedriver.exe that matches my web browser and dropped it into my project directory. Then I modified first_script.py to ensure that it calls that specific web driver also commented out the original code:
#driver = webdriver.Chrome() service = Service('C:\\py311seleniumbot\\chromedriver.exe') driver = webdriver.Chrome(service=service)Well it's using the new chromedriver.exe alright but I'm still getting the same cert error.
I'm at a loss on how to fix this. I need there to be a proper https connection to the remote website. I don't want to sweep this under the rug by using the "--ignore-certificate-errors" flag as that doesn't address the security concerns of a production environment.
Is there a kind soul in this wonderful Selenium community that can help a budding selenium enthusiast?
If I can get this pesky certificate issue resolved, I'm going to be well on my way to becoming a Selenium fanatic and very excited to start automating with this beauty.
-
Can't click captcha imgs elements
I try to use selunim to solve the capatha using ai but I have a problem in clicking the img of capatcha I don't know I try many methods like using javascript... To bypass it put it not work.. Url site : "https://algeria.blsspainglobal.com/DZA/account/login"
-
Weird behavior trying to scrape chase.com
I use selenium in python with chromedriver to scrape my bank account balances everyday so I don't have to log into multiple websites. I don't think Chase likes this and they actively try to stop it with their use of shadow roots, etc., but I've still managed to scrape Chase up till now. As of a couple weeks ago, I'm getting a really strange behavior, where if I run the python script there is an element not found error message for an element that clearly is there. Weirdly, if I put a breakpoint in the code and then simply resume execution once it hits the breakpoint then the element is found (by ID) and my script runs, but otherwise it doesn't. Timers don't help. I've tried sleeping for up to 20 seconds and the element is still not found, but something about hitting a breakpoint in the python script allows the element to be found. Anyone else run into this?
The line is:
element = driver.find_element("id", "requestAccounts") -
Is there a light weight selenium web driver for linux?
I had this question, found a privated reddit post, so I figured I'd ask again :)
I'm basically trying to figure out a minimal container that can load pages via selenium and take a screenshot.
"I am presently using a firefox gecko driver with python in ubuntu for my auto testing. The problem is it uses a very high memory about 150-350 mb and also cpu for a single site. Is there any lightweight selenium web drivers which uses less system resources? Can you recommend any? "
-
Java, JS or Python for Selenium WebDriver?
Manual QA here want to start learning Test Automation. Coming from a non-tech background will make it a bit of a challenge but I'm looking to "test" myself.
Out of the three languages (Java, JS, Py), which should I focus on learning to get the best knowledge to apply when eventually using Selenium WebDriver?
I would like to comprehend all three later on in the future but for now which is the best to start off or continue with. Many have mentioned Python is beginner-friendly approach to learning programming and less stressful, but I see a lot of tutorials for Selenium webdriver being taught using Java, Also I heard JS is being implemented a lot more and more nowadays.
-
{kind=link}